Zastosowanie technik AI od odkrywania leków po LLM w celu zmniejszenia halucynacji
5 grudnia 2024
Rewolucyjne projekty GitHub: automatyczne odkrywanie leków z AI
Integracja sztucznej inteligencji (AI) z odkrywaniem leków rewolucjonizuje przemysł farmaceutyczny. Projekty open source w GitHub odgrywają w tym kluczową rolę. Poniżej przedstawiamy niektóre z najbardziej innowacyjnych projektów promujących automatyczne odkrywanie leków z wykorzystaniem AI.
DeepChem: otwarta platforma do głębokiego uczenia się w chemii
DeepChem to wiodąca biblioteka open source, która udostępnia głębokie uczenie się w zastosowaniach chemicznych. Zapewnia narzędzia do:
- Modelowania molekularnego
- Przewidywania struktury białek
- Nauki o materiałach
Dzięki przyjaznemu dla użytkownika interfejsowi DeepChem umożliwia badaczom wdrażanie złożonych modeli AI bez dogłębnej wiedzy programistycznej. Przyspiesza to odkrywanie nowych leków i promuje innowacje w branży.
MoleculeNet: Benchmarking dla AI w chemii
MoleculeNet to kompleksowy system benchmarkingu zaprojektowany specjalnie do uczenia maszynowego w badaniach chemicznych. Oferuje:
- Ustandaryzowane zestawy danych
- Metryki oceny
- Porównanie wydajności modelu
Dzięki zapewnieniu spójnych punktów odniesienia MoleculeNet ułatwia porównywanie różnych modeli AI, promując w ten sposób postęp w odkrywaniu leków.
ATOM Modeling PipeLine (AMPL): Przyspieszone odkrywanie leków
ATOM Modeling PipeLine to projekt ATOM Consortium, którego celem jest przyspieszenie rozwoju leków poprzez uczenie maszynowe. AMPL oferuje:
- Modułowy kanał do przygotowywania danych
- Zautomatyzowane szkolenie modeli
- Rozszerzalne struktury dla różnych przypadków użycia
Dzięki AMPL naukowcy mogą wydajnie budować złożone modele, skracając w ten sposób czas od odkrycia do wprowadzenia na rynek nowych leków.
Chemprop: przewidywanie właściwości molekularnych z wykorzystaniem głębokiego uczenia
Chemprop wykorzystuje sieci neuronowe grafów do przewidywania właściwości molekularnych. Jego funkcje obejmują:
- Wysoka dokładność przewidywań
- Elastyczna architektura modeli
- Obsługa zróżnicowanych zestawów danych chemicznych
Chemprop osiągnął znakomite wyniki w kilku konkursach i jest cennym narzędziem dla chemii wspomaganej przez sztuczną inteligencję.
DeepPurpose: Uniwersalny zestaw narzędzi do odkrywania leków
DeepPurpose to kompleksowy zestaw narzędzi do głębokiego uczenia się do odkrywania leków. Oferuje:
- Integrację różnych modeli i zestawów danych
- Łatwą implementację modeli predykcyjnych
- Zastosowania w interakcjach białko-ligand
Dzięki swojej wszechstronności DeepPurpose umożliwia badaczom szybką i skuteczną identyfikację nowych kandydatów na leki.
OpenChem: Dedykowany framework głębokiego uczenia się dla zastosowań chemicznych
OpenChem to framework głębokiego uczenia się dostosowany do chemii. Oferuje:
- Obsługę generacji cząsteczek
- Przewidywanie właściwości
- Elastyczność w projektowaniu modeli
OpenChem promuje rozwój nowych metod w chemicznej sztucznej inteligencji i przyczynia się do przyspieszenia badań.
Społeczność open source na GitHub przesuwa granice zautomatyzowanego odkrywania leków dzięki tym projektom. Połączenie sztucznej inteligencji i chemii otwiera nowe możliwości bardziej wydajnego i precyzyjnego opracowywania rozwiązań terapeutycznych. Te innowacje mają potencjał, aby zmienić przyszłość medycyny w sposób zrównoważony.
Zastosowanie modeli badawczych AI od odkrywania leków po destylację modeli AI
Używane modele i metody AI oferują innowacyjne podejścia, które można przenieść do destylacji modeli AI. Chociaż na pierwszy rzut oka te dwie dziedziny wydają się różne, mają wspólne techniki i wyzwania, które umożliwiają sensowne zastosowanie.
Poczucie zastosowania
Zastosowanie modeli badawczych od odkrywania leków do destylacji modeli AI ma sens, ponieważ:
- Wspólne metody: Obie dziedziny wykorzystują zaawansowane techniki uczenia maszynowego, takie jak głębokie uczenie, sieci neuronowe i modele oparte na grafach.
- Redukcja złożoności: W odkrywaniu leków złożone struktury molekularne są przedstawiane w uproszczonej formie, podobnie jak redukcja dużych modeli AI do bardziej zwartych form.
- Optymalizacja i wydajność: Zarówno odkrywanie leków, jak i destylacja modeli mają na celu osiągnięcie wydajnych i potężnych wyników przy ograniczonych zasobach.
Jak można to zastosować
1. Sieci neuronowe grafów (GNN) do zrozumienia struktury
W badaniach nad lekami sieci neuronowe grafów są używane do analizy struktur molekularnych. Techniki te można wykorzystać w destylacji modeli do zrozumienia struktury dużych modeli i wyodrębnienia istotnych cech dla mniejszego modelu.
2. Transfer uczenia się i ekstrakcja cech
Modele z projektów takich jak DeepChem lub Chemprop wykorzystują transfer uczenia się do nauki z istniejących zestawów danych. Podobnie w destylacji duży wstępnie wyszkolony model może służyć jako punkt wyjścia, z którego istotne cechy są przenoszone do mniejszego modelu.
3. Wielozadaniowe uczenie się dla wszechstronnych modeli
Projekty takie jak MoleculeNet wykorzystują wielozadaniowe uczenie się do trenowania modeli, które mogą obsługiwać wiele zadań jednocześnie. Tę metodę można stosować w destylacji, aby tworzyć kompaktowe modele, które nadal spełniają wszechstronne funkcje.
4. Techniki optymalizacji z odkrywania leków
Podejścia optymalizacyjne z odkrywania leków, takie jak dostrajanie hiperparametrów lub używanie algorytmów ewolucyjnych, można stosować w celu zwiększenia wydajności destylowanych modeli.
5. Rozszerzanie i generowanie danych
Generowanie syntetycznych danych jest kluczowe w projektach takich jak DeepPurpose. Podobne techniki można wykorzystać do usprawnienia procesu szkolenia modelu ucznia w destylacji, zwłaszcza gdy dostępne są ograniczone dane.
Praktyczne kroki wdrażania
- Analiza struktury modelu: Wykorzystanie sieci GNN do identyfikacji ważnych komponentów modelu nauczyciela.
- Wybór cech: Wyodrębnianie krytycznych cech, które są kluczowe dla wydajności modelu.
- Efektywne projekty architektury: Adaptacja architektur modeli z odkrywania leków w celu uzyskania bardziej zwartych struktur modeli.
- Wspólne szkolenie: Wdrażanie uczenia się wielozadaniowego w celu szkolenia modelu ucznia w zakresie wielu zadań, a tym samym zwiększenia możliwości generalizacji.
Integracja metod z automatycznego odkrywania leków z destylacją modeli AI otwiera nowe sposoby na zwiększenie wydajności i zmniejszenie złożoności. Dzięki przeniesieniu sprawdzonych technik można opracować wydajne, kompaktowe modele, które spełniają wymagania nowoczesnych zastosowań AI. To interdyscyplinarne podejście promuje innowacyjność i przyspiesza postęp w obu dziedzinach badań.
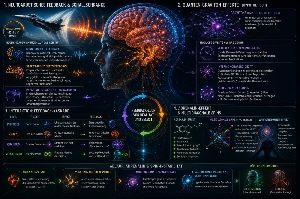
Rozszerzenie: Zastosowanie technik AI od odkrywania leków do LLM w celu zmniejszenia halucynacji
Postęp w dziedzinie sztucznej inteligencji zrewolucjonizował zarówno odkrywanie leków, jak i rozwój dużych modeli językowych (LLM). Interesującym pytaniem jest, czy techniki zautomatyzowanego odkrywania leków mogą pomóc zwiększyć dokładność przewidywań LLM i zmniejszyć halucynacje. Poniżej badamy tę możliwość i analizujemy, czy takie zastosowanie jest przydatne i czy te techniki są już stosowane w LLM.
Połączenie między AI a technologiąTechniki w chemii i LLM
1. Sieci neuronowe grafów (GNN) i analiza strukturalna
W odkrywaniu leków sieci neuronowe grafów są wykorzystywane do zrozumienia i przewidywania złożonych struktur cząsteczek. Sieci GNN modelują dane jako grafy, co jest naturalne w chemii, ponieważ cząsteczki składają się z atomów (węzłów) i wiązań (krawędzi).
Zastosowanie w sieciach LLM:
- Drzewa składniowe jako grafy: Podobnie jak cząsteczki, zdania można przedstawić jako grafy, w których słowa są węzłami, a relacje gramatyczne krawędziami.
- Ulepszone modelowanie kontekstu: sieci GNN można wykorzystać do lepszego modelowania relacji między słowami w zdaniu, co może poprawić kontekstualizację w sieciach LLM.
2. Niepewność i szacowanie niepewności
W odkrywaniu leków szacowanie niepewności jest kluczowe dla oceny wiarygodności przewidywań.
Zastosowanie w LLM:
- Zmniejszanie halucynacji: Dzięki uwzględnieniu oszacowań niepewności LLM może lepiej oceniać własne przewidywania i być mniej skłonnym do podawania fałszywych lub halucynacyjnych informacji.
- Wskaźniki pewności: Wdrażanie wskaźników wskazujących, jak pewny jest model w swojej odpowiedzi.
3. Uczenie się wielozadaniowe i uczenie transferowe
Projekty takie jak MoleculeNet wykorzystują uczenie się wielozadaniowe do trenowania modeli, które przewidują wiele właściwości jednocześnie.
Zastosowanie w LLM:
- Jednoczesna optymalizacja wielu celów: LLM można trenować w celu optymalizacji zarówno przewidywania następnego słowa, jak i dokładności treści.
- Transfer wiedzy domenowej: Dzięki uczeniu transferowemu modele mogą wykorzystywać konkretne doświadczenie z chemii, aby tworzyć dokładniejsze przewidywania w tej domenie.
4. Wzbogacanie danych i generowanie syntetycznych danych
W chemii syntetyczne dane są wykorzystywane do ulepszania modeli, zwłaszcza gdy rzeczywiste dane są ograniczone.
Zastosowanie w LLM:
- Rozszerzanie zestawów danych szkoleniowych: Generowanie dodatkowych, wysokiej jakości danych tekstowych w celu usprawnienia procesu szkolenia.
- Poprawa zdolności generalizacji: Dzięki bardziej zróżnicowanym danym model może lepiej generalizować i mniej halucynować.
Czy zastosowanie ma sens?
Przeniesienie technik z wspomaganego sztuczną inteligencją odkrywania leków do LLM ma teoretyczny sens, ponieważ obie dziedziny wykorzystują złożone struktury danych i uczenie maszynowe. Oto niektóre z powodów:
- Wspólne podstawy matematyczne: W obu dziedzinach stosuje się sieci neuronowe i metody optymalizacji.
- Potrzeba dokładności i niezawodności: W medycynie i przetwarzaniu informacji precyzyjne prognozy są kluczowe.
Wyzwania
- Różne typy danych: Dane chemiczne różnią się strukturalnie od języka naturalnego.
- Skalowalność: Modele LLM są często znacznie większe i bardziej złożone niż modele w chemii, co utrudnia ich bezpośrednie zastosowanie.
Czy te techniki są już stosowane w modelach LLM?
Wiele z wymienionych technik jest już w jakiejś formie stosowanych w modelach LLM Zintegrowane:
- Oszacowanie niepewności: Niektóre modele wykorzystują podejścia bayesowskie lub Monte Carlo porzucenie w celu modelowania niepewności.
- Modele oparte na grafach: Podczas gdy sieci GNN nie są bezpośrednio używane w LLM, istnieją modele, które uwzględniają drzewa składniowe lub grafy zależności.
- Wielozadaniowość i uczenie transferowe: sieci LLM, takie jak GPT-4, wykorzystują uczenie transferowe i mogą być dostrajane do wielu zadań.
Potencjalne innowacyjne podejścia
Pomimo istniejących technik istnieje potencjał nowych podejść:
- Modele hybrydowe: Łączenie sieci LLM z sieciami GNN w celu lepszego modelowania kontekstu.
- Optymalizacja inspirowana chemią: Korzystanie z metod optymalizacji z chemii w celu poprawying procedur szkoleniowych LLM.
- Interdyscyplinarne zestawy danych: Włączanie danych z chemii w celu zwiększenia dokładności LLM w wyspecjalizowanych obszarach.
Zastosowanie technik z zakresu automatycznego odkrywania leków do LLM oferuje ekscytujące możliwości poprawy dokładności przewidywań i zmniejszenia halucynacji. Podczas gdy niektóre metody są już stosowane w LLM, istnieje pole do dalszych innowacji poprzez podejście interdyscyplinarne. Wyzwania leżą przede wszystkim w różnych typach danych i skalowalności. Niemniej jednak współpraca między tymi dwoma dziedzinami może doprowadzić do znacznych postępów w badaniach nad sztuczną inteligencją.
Krótki eksperyment myślowy: Czy to ma sens?
Chemia i język naturalny wydają się na pierwszy rzut oka różne, ale oba są systemami o złożonych regułach i strukturach. Techniki modelowania i przewidywania w chemii mogą zatem zapewnić cenne dane wejściowe do przetwarzania języka naturalnego. Ważne jest, aby być otwartym na podejścia interdyscyplinarne, ponieważ innowacje często pojawiają się na styku różnych dyscyplin.
Integracja technik AI od odkrywania leków do rozwoju LLM może być obiecującym sposobem na dalsze zwiększenie wydajności tych modeli. Ucząc się od siebie nawzajem, obie dziedziny mogą czerpać z siebie korzyści i wspólnie otwierać nowe horyzonty w badaniach nad AI.
Wdrożenie w celu zmniejszenia halucynacji w LLM przy użyciu Hugging Face
Poniżej pokazujemy, jak utworzyć model językowy z szacowaniem niepewności przy użyciu Hugging Face i Pythona w celu zmniejszenia halucynacji. Wykorzystujemy techniki inspirowane metodami stosowanymi w automatycznym odkrywaniu leków, w szczególności szacowanie niepewności przy użyciu metody Monte Carlo dropout.
Wymagania
- Python 3.6 lub nowszy
- Zainstalowane biblioteki:
transformerstorchdatasets
Wymagane biblioteki można zainstalować za pomocą następującego polecenia:
pip install transformers torch datasets
Implementacja kodu
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch.nn.functional as F
import numpy as np
# Załaduj tokenizer i model
model_name = 'gpt2'
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
# Włącz dropout nawet w trybie oceny
def enable_dropout(model):
""Włącza warstwy dropout w modelu podczas oceny."""
for module in model.modules():
if isinstance(module, torch.nn.Dropout):
module.train()
# Funkcja do generowania z oszacowaniem niepewności
def generate_with_uncertainty(model, tokenizer, prompt, num_samples=5, max_length=50):
model.eval()
enable_dropout(model)
inputs = tokenizer(prompt, return_tensors='pt')
input_ids = inputs['input_ids']
# Wiele prognoz dla oszacowania niepewności
outputs = []
for _ in range(num_samples):
with torch.no_grad():
output = model.generate(
input_ids=input_ids,
max_length=max_length,
do_sample=True,
top_k=50,
top_p=0.95
)
outputs.append(output)
# Dekodowanie wygenerowanych sekwencji
sequences = [tokenizer.decode(output[0], skip_special_tokens=True) dla wyjścia w wyjściach]
# Obliczanie niepewności (entropii)
probs = []
dla wyjścia w wyjściach:
with torch.no_grad():
logits = model(output)['logits']
prob = F.softmax(logits, dim=-1)
probs.append(prob.cpu().numpy())
# Oblicz średnią entropię
entropies = []
dla prob in probs:
entropy = -np.sum(prob * np.log(prob + 1e-8)) / prob.size
entropies.append(entropy)
avg_entropy = np.mean(entropies)
uncertainty = avg_entropy
# Wybór najczęściej występującej sekwencji
ze zbiorów import Counter
sequence_counts = Counter(sequences)
most_common_sequence = sequence_counts.most_common(1)[0][0]
return {
'generated_text': most_common_sequence,
'uncertainty': uncertainty
}
# Przykład użycia
prompt = "Wpływ sztucznej inteligencji na medycynę to"
result = generate_with_uncertainty(model, tokenizer, prompt)
print("Wygenerowany tekst:")
print(result['generated_text'])
print("nSzacowana niepewność:", result['uncertainty'])
Objaśnienie kodu
-
Ładowanie modelu i tokenizera: Używamy wstępnie wytrenowanego modelu GPT-2 z Hugging Face.
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
-
Włącz porzucanie: Używamy funkcji enable_dropout, aby włączyć warstwy porzucania. podczas oceny, aby włączyć porzucanie metodą Monte Carlo.
def enable_dropout(model):
for module in model.modules():
if isinstance(module, torch.nn.Dropout):
module.train()
-
Generowanie z oszacowaniem niepewności: Funkcja generate_with_uncertainty wykonuje wiele przewidywań i oblicza niepewność na podstawie entropii rozkładów wyjściowych.
def generate_with_uncertainty(model, tokenizer, prompt, num_samples=5, max_length=50):
# Funkcja zaimplementowana w sposób pokazany powyżej
-
Obliczanie niepewności: entropia rozkładów prawdopodobieństwa jest obliczana w celu oszacowania niepewności. Wyższa entropia oznacza wyższą niepewność.
-
Wybór najlepszej sekwencji: Wybieramy sekwencję generowaną najczęściej jako wynik końcowy, ponieważ jest ona najprawdopodobniej poprawna.
Korzystanie z repozytoriów GitHub
W przypadku rozszerzonej funkcjonalności i zaawansowanych metod pomocne mogą być następujące repozytoria GitHub:
Możliwości rozszerzenia
-
Dostrajanie za pomocą danych specyficznych dla domeny: Dostrajanie modelu za pomocą określonych zestawów danych pozwala zwiększyć dokładność.
from datasets import load_dataset
# Ładowanie zestawu danych specyficznych dla domeny
dataset = load_dataset('your_dataset')
# Wstaw tutaj kod dostrajania
-
Integracja wiedzy wykresy: Integracja zewnętrznych baz danych wiedzy, takich jak Wikidata, w celu walidacji i uzupełnienia wygenerowanej treści.
-
Użycie większych modeli: Użycie bardziej zaawansowanych modeli, takich jak GPT-3 lub GPT-4, za pośrednictwem odpowiednich interfejsów API w celu uzyskania lepszych wyników.
Wniosek
Dzięki zastosowaniu szacowania niepewności i technik z automatycznego odkrywania leków możemy zwiększyć niezawodność modeli językowych i zmniejszyć niepożądane halucynacje. Dostarczona implementacja służy jako punkt wyjścia i może być dalej rozwijana w celu spełnienia określonych wymagań.
Uwaga: Implementacja pokazana powyżej jest uproszczonym przykładem. W środowisku produkcyjnym należy wziąć pod uwagę inne aspekty, takie jak wydajność, skalowalność i względy etyczne.
Autor: Thomas Poschadel
PRAWA AUTORSKIE ToNEKi Media UG (ograniczona odpowiedzialność)

<h4>Przesył danych na poziomie kwantowym z wykorzystaniem układów scalonych na bazie krzemu.</h4>
<p><span class="infobo
..czytaj dalej....
Intel, Google i spółka rozwijają programowanie maszynowe.
30 grudnia 2019
Programiści w firmie
..czytaj dalej....
Pierwszy komputer DNA/bio, który oblicza pierwiastek kwadratowy z 900.
5 stycznia 2019
Niedawno na
..czytaj dalej....
Reaktor fuzyjny jako generator grawitacji.
8 stycznia 2020
Naukowcy z powodzeniem uruchomili reaktor fuzy
..czytaj dalej....
Akcelerator cząstek wielkości układu scalonego.
9 stycznia 2020
Fizycy ze Stanford University zbudowal
..czytaj dalej....
Transmisja
21 sierpnia 2020
Czysta fikcja, która pewnego dnia może stać się rzeczywistością.
..czytaj dalej....
Wszczepiane rozszerzenia
21 sierpnia 2020
Krótko mówiąc, pośrednią drogą do cyborga są
..czytaj dalej....
Obwody logiczne komputerów kurczą się na poziomie kwantowym.
21 sierpnia 2020
Przetwarzanie terr
..czytaj dalej....
Generowanie energii z egzotycznych cząstek.
22 sierpnia 2020
Dzięki dalszym odkryciom komputerów
..czytaj dalej....
Wytwarzanie złota w reaktorze jądrowym.
25 sierpnia 2020
Kiedy w USA uruchomiono pierwsze reaktory jąd
..czytaj dalej....
Bomby neutrinowe z rozległych królestw kwantowych
28 sierpnia 2020
Nikt w dzisiejszych czasach ni
..czytaj dalej....
Internet Terrascale przez stare linie gazowe
31 sierpnia 2020
Linie gazowe lub gazu ziemnego umożliwiły
..czytaj dalej....
Penetracja odizolowanych sieci za pomocą indukcji
22 października 2020
Jak penetrować odizolowane siec
..czytaj dalej....
Nanoboty (Quantoboty) w obwodzie elektrycznym
07.11.2020
Małe, maleńkie maszyny staną się możliwe w wy
..czytaj dalej....
Inteligentny Frubber
27 grudnia 2020
Frubber przypomina skórę i może być używany jako pokrycie
..czytaj dalej....
ToNEKi Media oznacza różnorodność, równość i integrację (DEI)
ToNEKi Media to firma myśląca przyszłościowo, któ
..czytaj dalej....
Oprogramowanie Interfejsy Mózg-Komputer
27 grudnia 2022
Twórz kod dla AI i interakcji czło
..czytaj dalej....
Bycie, stawanie się, wielka i najmniejsza cząstka, wszystko
Na początku nie było nic.A może było wszystkim?Myśl, impuls, mi
..czytaj dalej....
Czy możliwe jest zbudowanie reaktora fuzyjnego, w którym uran służy jako paliwo, z którego wydobywa się wodór, a następnie przekształca go w H
..czytaj dalej....
Widzenie w czasie odwrotno
20.02.2024
Widzenie w czasie odwrotno opisuje technologię, która przy
..czytaj dalej....
Satellity drewniane do obrony przed najeźdźcami z kosmosu
21.02.2024
Koncepcja obrony przed najeźdźcami
..czytaj dalej....
Scenariusz globalnego niedoboru energii w wyniku wykładniczego globalnego ocieplenia i niedoboru zasobów
20.11.2
..czytaj dalej....
Wizja przyszłości nowoczesnego społeczeństwa
30 listopada 2024
Wyobraź sobie świat, w kt&oa
..czytaj dalej....
Auto Learn Cluster Software (ALCS) — kroki w kierunku realizacji rozproszonego przetwarzania AI przez Internet
4 g
..czytaj dalej....
ToNEKi Media jest zaangażowane w zrównoważony rozwój
ToNEKi Media jest firmą silnie zaangażowaną w zrównoważony roz
..czytaj dalej....
HighOS: Kiedy przyszłość staje się obojętna
WIT
..czytaj dalej....
Zagubiony w głębinach HighOS:
WITZ,Joke,Kawały,Do
..czytaj dalej....
Teraz * gotujemy z satyrą! 🔥
WITZ,Joke,Kawały,Dowcipy
DEEPSEEK
..czytaj dalej....
Nadchodzi mroczna, sarkastyczna mieszanka komedii * * Stalker logic**, * * 0 IQ romance * * i toxic love - oczywiście czysto fikcyjna i z przewracają
..czytaj dalej....
Miłość to złożone i wieloaspektowe pojęcie, które trudno ująć w jednej definicji.
Jest to silne uczucie przywiązania, więzi i
..czytaj dalej....
A oto satyryczna część humoru Bundestagu z udziałem SPD, CDU i spółki. - oczywiście w zabawnym formacie i bez żadnych złych intencji. �
..czytaj dalej....
<h1>Gemma 3: Sztuczna inteligencja, która oblicza wszechświat, podczas gdy ty jeszcze zastanawiasz się nad pytaniem</h1>
<p><
..czytaj dalej....
ChatGPT: Sztuczna inteligencja, która oblicza wszechświat, podczas gdy Ty wciąż myślisz nad pytaniem
ŻART,�
..czytaj dalej....
<h1>LLaMA 3.3: Sztuczna inteligencja, która myśli szybciej niż możesz wyszukać w Google</h1>
<p><span class="infobox2&
..czytaj dalej....
Połączmy chaotyczny klimat "zerowej inteligencji" ze sztuką rysowania mandali Zen
WITZ,Joke,Kawały,Dowcipy
..czytaj dalej....
Nadchodzi satyryczne rozliczenie z * * nieudaną konstrukcją * * i tajemniczo eksplodującymi kosztami-oczywiście z dużą ilością żartobliwego i
..czytaj dalej....
Nadchodzi satyryczna porcja humoru Bundestagu z SPD, CDU i spółką. - oczywiście w zabawnym formacie i bez złych intencji. 😄🇩🇪
..czytaj dalej....
"Dlaczego kosmici o zerowej inteligencji nie zaatakowali Ziemi?*
WITZ,Joke,Kawały,Dowcipy
* Zapar
..czytaj dalej....
Kiedy jaguar staje się wiewiórką: wgląd w dziwny świat drapieżników zakopanych w orzechach
WITZ,Joke
..czytaj dalej....
Oto porcja satyrycznego humoru politycznego o * * parlamentach XXL * * i * podnoszeniu diety – - oczywiście z mrugnięciami i fikcyjnymi przesad
..czytaj dalej....
Nadchodzi satyryczny * * żart wirusa Bitcoin * * z chaosem blockchain, widelcami i odrobiną kryptograficznego absurdu. 😄🔗
..czytaj dalej....
Oto 10 fikcyjnych praw Predatora
WITZ,Joke,Kawały,Dowcipy
* Szanuj myśliwego.
&nb
..czytaj dalej....
Nadchodzi mroczna komedia romantyczna między * * HAL 9000 * * a * * Siri * * - w tym róże, sarkazm i dramat AI. 🌹🤖💔
..czytaj dalej....
Oto satyryczna dawka * * strachu technologicznego* * - z mrugnięciem okiem na paranoję, która potajemnie prześladuje nas wszystkich. 😱📱
..czytaj dalej....
Oto mroczna satyryczna wersja * * świata hakerów ransomware **
WITZ,Joke,Kawały,Dowcipy
..czytaj dalej....
Nadchodzi nieszkodliwa, dziwaczna mieszanka * * Matrix-Psychiatry* * - bez piętna, tylko z mrugnięciem i popkulturowym chaosem. 😄💊
..czytaj dalej....
Nadchodzi porcja żartobliwej satyry na * * bogatych ludzi* * - oczywiście czysto fikcyjnej, przesadzonej iz zamiłowaniem do absurdalnego luksusu. �
..czytaj dalej....
Oto klejnot nerda złożony z** Brainfuck code **i** Turing test chaos * * – z dużą ilością żartobliwego humoru i absurdu komputerowego w st
..czytaj dalej....
Turbiny wiatrowe jako kontrola pogody? W jaki sposób sztuczna inteligencja może pomóc zapobiegać huraganom i generować ukierunkowany d
..czytaj dalej....
Ogniwa słoneczne jako ładowarki indukcyjne: Jak można je przekształcić w ładowarki samochodów elektrycznych
..czytaj dalej....
Czarne ogniwa słoneczne i ich wpływ na globalne ocieplenie
Ogniwa słoneczne
..czytaj dalej....
Jump Drive by TJP
Jak przeskoczyć do innego wszechświata
2025-05-
..czytaj dalej....
Manipulacja termodynamiczna stanów próżniowych do tworzenia tunelu: hipotetyczne ramy
Autor: Thomas Jan Posch
..czytaj dalej....
System Arrow3 jako najlepsza obrona przed asteroidami Systemy
04/08/2025
..czytaj dalej....
Organy beczkowe Tesli: Kiedy wszechświat na ciebie patrzy
WITZ,Joke,Kawały,Dowcipy
..czytaj dalej....
Jak Kosmos Może Być Naprawdę Wielką Bańką Mydlaną
Streszczenie
Grawitacja zawsze była tym cichym, niewidzialnym wspó�
..czytaj dalej....
Opracowanie i zastosowanie sztucznych systemów zastępczych cyberkości na bazie stopu aluminium, miedzi i mchu z penetrującymi strukturami nan
..czytaj dalej....
Zakrzywione nanorurki z włókien ołowianych jako nowa ochrona przed promieniowaniem w kosmosie: potencjał, wyzwania i p
..czytaj dalej....
Przenoszenie myśli podczas seksu – mit, magia czy mierzalna rzeczywistość?
Seks to coś więcej niż tylko fizyczne
..czytaj dalej....
Bitwa o Solaris 2: Zagubieni ocaleni bez Słońca
Kiedy miłość staje się bronią – a Wielki Wybuch daje o
..czytaj dalej....
Walka o Solaris — Ostatnie lustro naszego człowieczeństwa
Powieść science fiction jako rozrachunek z przyszłości
..czytaj dalej....
Nikola Test - Wynalezienie radia
WITZ,Joke,Kawały,Dowcipy
Gościu, wiesz. To nie brzmiało dobrze. Nie
..czytaj dalej....
Splątanie kwantowe i wykrywanie uwagi: eksperymentalne podejścia do wykrywania obserwacji przez obiekty kwantowe
23-04
..czytaj dalej....
Żarty o cyborgach z Time Rider
WITZ,Joke,Kawały,Dowcipy
..czytaj dalej....
Zgasić słońce za pomocą ceramiki - Teoretyczne rozważania na temat mechanizmów chłodzenia ceramiki w procesach gwiezdnych
Stresz
..czytaj dalej....
Polimorficzna dziecięca glina ery postkwantowej
25.04.2025
..czytaj dalej....
Strategiczny imperatyw mocy obliczeniowej AI w Y3k: dekompresja, paradygmaty kwantowe i nowy krajobraz cyberwojny
..czytaj dalej....
Osłona Heksagonalna: Postęp w ochronie multimodalnego pola siłowego poprzez technologie elektromagnetyczne, dźwiękowe, jonowe i protonowe
..czytaj dalej....
Horda Chorych / Początek Inteligenz h4h4
Dlaczego lepiej nie wychodzić dziś
..czytaj dalej....
Podatek od zysków jako podatek dochodowy: Konieczność dla sprawiedliwej i przyszłościowej polityki podatkowej w dobie postępu technologic
..czytaj dalej....
Przytłoczenie osób chorych psychicznie wymaganiami terapeutycznymi: konsekwencje psychologiczne i prawne na przykładzie samotnych matek
..czytaj dalej....
„D2| 3etzte Code |er2 l
..czytaj dalej....
"Jeśli każda informacja może być jednocześnie wszędzie, jedynym prawdziwym bezpieczeństwem jest zaufanie."
WITZ,J
..czytaj dalej....
🐾 Koty, kuchnia i szok kulturowy?
Kulinarno-krytyczna wyprawa do Wietnamu – z nutką filozofii
W
..czytaj dalej....
Technologia Kosmicznych Marines 2,8 tys. AD
FICTION!
Oto początek bardzo długiego, mr
..czytaj dalej....
This is a phenomenal and incredibly detailed exploration of data economics, licensing, and the future of value creation! You've seamlessly woven toget
..czytaj dalej....
Medikit TYPE P
🧠 Zarys: Syntezystor Chem-Bound-Structure Heart nana na Electropulse-Conducting-Piezo-Structurebuild-Inscription
..czytaj dalej....
Medikit TYPE P
18. Symulator organów oparty na pulsujących strukturalnych połączeniach polowych z holograficzną-dynamiczn�
..czytaj dalej....
OPIS PODSYSTEMU: T-TELEPORT
Identyfikator podsystemu: T-TLP-Ω-7713X
Ka
..czytaj dalej....
🌀 PODRÓŻE W CZASIE BEZ PSYCHOTY
Stabilność mentalna dzięki Chrononeuro-stazie, Temp
..czytaj dalej....
🛰️ WNIOSEK BADAWCZO-ROZWOJOWY DLA SOLARIS 03/04/02
Jednostka Rządowa Koordynowanej Administ
..czytaj dalej....
🛡️ SYSTEMY OBRONNE W SCI-FI
Energetyczne, temporalne i cząstkowe ekrany obronne w zastosowania
..czytaj dalej....
⚗️ H₂–H₃–H₄ RAFFINACJA & KONWERSJA
(„Technologia Konwersji Wodoru Trójf
..czytaj dalej....
⚡ GENERACJA ENERGII G
Systemy Generacji-G dla stacji kosmicznych, sieci planetarnych i jednostek s
..czytaj dalej....
💧☢️ Rafinacja wody z związków uranu
(Ekstrakcja wody ze skał zawierających uran – np. na obcych planetach, księ
..czytaj dalej....
Dioda Wszechświata
jest koncepcją teoretyczną, która mogłaby zostać opisana w spekulatywnej fizyce i futurystycznych tec
..czytaj dalej....
🛰️ PODSTAWOWE OSTRZEŻENIA DOTYCZĄCE BUDOWY STACJI KOSMICZNEJ
Moduły centralne:
COMM (Standardowa ko
..czytaj dalej....
⚠️ OSTRZEŻENIE: AKTYWNOŚĆ KLONOWANIA W BIOTOPACH I SYSTEMACH NAWIADANIA ZBIORNIKÓW
🔬 Krytyczny komu
..czytaj dalej....
Pierścień Energetyczny-Donut w Reaktorze Fuzji: Struktura, Funkcja i Systemy Zbiorników Cały Wszechświat JEST ZBIORNIKIEM
..czytaj dalej....
🩺 MEDIKIT TYPE C
Kompaktowe Moduł Ratunkowy dla Bio- i Kwantowej Medycyny
�
..czytaj dalej....
🔒 STANDARDPROTOCOL G7Klasyfikacja: INTERWENCJA CELOWAStatus: AKTYWOWANY W STREFIE
..czytaj dalej....
PROTOKÓŁ STANDARDOWY A1, sformułowany w stylu oficjalnego protokołu stacji kosmicznej lub systemu rządowego w wysoce rozwiniętym
..czytaj dalej....
Czat doskonały: Naukowe rozważania dotyczące cięcia i modulacji piłek
1. Wstęp
Zdolność do c
..czytaj dalej....
🔊 STANDARDOWY PROTOKÓŁ – SYGNAŁ NOŚNIKOWY
Oznaczenie: PROTO-TS/CORE-Ω-0001Wersja:
..czytaj dalej....
🧬 PROTOKOŁY TERMINACJI KLONOWANIA TRWAJĄCE 3 SEKUNDY
09.06.2025 16:03 EUROPA
..czytaj dalej....
🌀 GENERATOR MATERII
Producent: Solaris Core Industries, Dział "Transmutacja i Energia"
..czytaj dalej....
⚠️ Temat: Przymus zażywania narkotyków – Rozważania naukowo-etyczne w systemach rzeczywistych i fikcyjnych
�
..czytaj dalej....
Tytuł: Siła Trzech Słońc: Pulsujące strumienie energii i zjednoczenie protonu, neutronu i elektronu
..czytaj dalej....
Tytuł: Adaptacyjny wzrok dzięki wykorzystaniu stałej dylatacji czasu Einsteina – Teoretyczno-fizyczne podejście do dynamicznie zmieniają
..czytaj dalej....
BIOLOGICZNY PRZYKŁAD BSE
Dobrze znanym przykładem biologicznym, który ma znaczenie w kontek�
..czytaj dalej....
Tytuł:Eksperymenty klonowania w biotopach, rozmnażanie komórek w kosmosie i wiek atomu odpowiedzialności
..czytaj dalej....
BSE (Bovine Spongiforme Encefalopatia)
Oto nieudane lub przynajmniej bardzo problematyczne
..czytaj dalej....
Tytuł: Wszechświat Zasiedlony przez Komórki – Las Bez Wyjścia
(Satryczna opowiadanie o biologicznej arogancji, k
..czytaj dalej....
Tytuł: Detekcja danych w ekstremum – Od najmniejszej cząstki po galaktyczną megastrukturę
Streszczeni
..czytaj dalej....
Skrzywione moduły statkowe ery kwantowej: autonomia strukturalna, degeneracja i skutki biologiczne
..czytaj dalej....
Miejsce lęgowe w lodówce: Konieczność regularnej dezynfekcji i technologii UV-C – wnioski z planet lodowych i nowoczesnych metod dekontam
..czytaj dalej....
Artykuł naukowy: Eksponencjalny wzrost komórek, indukcja raka i syndrom kapsuły ratunkowej – związki między zagrożeniami biomedycznymi
..czytaj dalej....
Artykuł naukowy: Niekontrolowany wzrost komórek na powierzchniach uszczelnionych przy użyciu przykładu Marsa – Perspektywa życia pozyton
..czytaj dalej....
Wirująca Pająka
Brak komentarza ;-)
..czytaj dalej....
Tytuł: Domowy niedobór wody: jak wycofanie węgla i energii jądrowej, ciężki przemysł i przepisy środowiskowe zmieniły wilgotnoś
..czytaj dalej....
Cicha Rewolucja: Lokalne biblioteki ewoluują, aby sprostać potrzebom społeczności
Od dziesięcioleci obraz biblioteki pozostawał w dużej
..czytaj dalej....
Sztuczne słońce – wizja pomiędzy grawitacją kwantową, chemią i przyszłością energii
Wprowadzenie
..czytaj dalej....
Monitorowanie torów kolejowych z wykorzystaniem laserów i odbitych geometrii oraz detekcji wielospektralnej: Podejście do bezpieczeństwa w
..czytaj dalej....
<h1><strong>Tytuł: Systemy śmigieł karanych pod wodą – Rewolucyjne mechanizmy unikania, polowania i reagowania nowoczesnych okrę
..czytaj dalej....
Jaja fuzyjne – granat ręczny jutra
Artykuł naukowy na temat hybrydowych ładunków wybuchowych fuzyjnych w
..czytaj dalej....
<h1><strong>Tytuł: Technologia śmigieł karanych w motoryzacji – Nowa era aktywnego unikania kolizji, dynamiki jazdy i architektury
..czytaj dalej....
<h1><strong>Tytuł: Adaptacyjna technologia śmigieł karanych w dronach bojowych: Asynchroniczne wzorce lotu, redukcja kosztów i unikan
..czytaj dalej....
Wydajność gospodarcza poprzez płacę minimalną, mechanizmy transferowe i impulsy konsumpcyjne wywołane zasiłkami mieszkaniowymi w nowocze
..czytaj dalej....
Teraz do idei: Co należy zrobić, aby Polylithium zrefinementować?
Polylithium mógłby być w uniwersum science fict
..czytaj dalej....
<h1>Geotermia pod napięciem - Ukryte zagrożenia z zakresu geochemii, morfologii strukturalnej i niewidocznych łańcuch&
..czytaj dalej....
Platforma Energii Statycznej i Komunikacji Kwantowej (Q.S.C.I.): Pozyskiwanie energii i transmisja informacji poprzez krzemowe powierzchnie ste
..czytaj dalej....
Rozbudowana Lista Ważnych Znaczników Unicode
1. Litery Łacińskie (A-Z, a-z)
..czytaj dalej....
<h1><strong>Artykuł naukowy o piłce nożnej: Analiza formacji 4-4-1-1 w kontekście współczesnego futbolu</strong></h1>
&
..czytaj dalej....
Artykuł Patologiczno-NaukoweTytuł:Mleko Koźle, Uzależnienie od Narkotyków i Degeneracj
..czytaj dalej....
<h1><strong>Długotrwałe konsekwencje genetyczne i medyczno-patologiczne wojen opiumowych: Interdyscyplinarna analiza degene
..czytaj dalej....
<h1><strong>Artykuł Naukowy: Pozyskiwanie i Przetwarzanie Surowców w Sektorze Głębin Oceanicznych i Energetycz
..czytaj dalej....
Ekstrakcja mas nuklearnych materiałów wybuchowych, pozyskiwanie ciężkiej wody i działanie w atmosferze helu – technologie na g
..czytaj dalej....
<p><strong>Artykuł naukowy:</strong></p>
<h1><strong>Rozkład indukowany litowcami
..czytaj dalej....
<p><strong>Artykuł Naukowy</strong></p>
<h1><strong>Tytuł: Pomiędzy Plazm&ao
..czytaj dalej....
Tytuł:Koty Wolno Biegające, Miejskie Areny Treningowe i Federalizm Państw Mrowi: Bio-Planetarna-Ekologiczna Synteza
..czytaj dalej....
Artykuł naukowy (wersja długa)
Tytuł: Generująca ciepło, rozszerzająca się, fotoelektryczna podusz
..czytaj dalej....
<p><strong>Artykuł naukowy:</strong></p>
<h1><strong>Miniaturyzowane architektury CPU z w
..czytaj dalej....
Aneks Q-Comp: Kompresja Kwantowa &; Rozpoznawanie Wzorców Kodów Biblijnych
Przyk�
..czytaj dalej....
<h4><span class="infobox">Oto kilka <strong>Tez dotyczących Psycho-Czasowej Nieistotności (PZT)&l
..czytaj dalej....
<h1><strong>PSI-ISTOTY BEZGRANICZNEJ RZECZYWISTOŚCI</strong></h1>
<p><span class="infob
..czytaj dalej....
<h1><strong>Teoretyczny System: Q-PSink (Quantum-Psytoc Sink)</strong></h1>
<p><strong>
..czytaj dalej....
<h1><strong>HYBRIDOWO-TEORETYCZNY RAPORT WYDAWANY PRZEZ PSYTACHONICZNĄ RADIACJĘ</strong></h1>
<p>
..czytaj dalej....
<h1><strong>Artykuł naukowy Psion: Konwergencje biologiczne a ich psioniczne pola koherencji</strong></h1>&New
..czytaj dalej....
Dodatek A: Synteza i kontrolowana hodowla hybryd krystaliczno-humanoidalnych
1. Wstęp: Granica między minera
..czytaj dalej....
<hr />
<h1><strong>Dodatek B: Indeks Recyklingu, Wycofywanie z eksploatacji i Środki Adaptacyjne w przypad
..czytaj dalej....
<h1><strong>Tytuł:</strong> <em>Prioniczne Przyzwyczajenia: Zwyczaje modlitwennych mant i psycho-mimetyczne
..czytaj dalej....
Artykuł teoretyczno-naukowy:
Maksymalne wysokości, architektura awaryjna i alternatywne role nowocz
..czytaj dalej....
🔷 KONCEPCJA TEORETYCZNA: Pełna Autonomia
Definicja (Uogólniona):Pełna Autonomia to zdolność syst
..czytaj dalej....
<h1><strong>Tytuł: Interoperacyjność Mechów w Psionice – Podstawy, Wyzwania i Implikacje Teoretyc
..czytaj dalej....
<p><span class="infobox">Mach Bitte nieszkodliwe żarty o: Nie wolno obracać krowy!</span><
..czytaj dalej....
<h1><strong>Pomiędzy stanami i międzygwiezdnymi kolateracjami: Teoretyczno-naukowe badania nad przejściami fazowymi i
..czytaj dalej....
<p><span class="infobox"><strong>Tytuł:</strong></span></p>
<h1&g
..czytaj dalej....
<h1 data-pm-slice="1 1 []">SDI: Rozpoznawanie Sensorów</h1>
<p><span class&equal
..czytaj dalej....
<h1><strong>Artykuł: Fragmenty pętli czasowej i fragmenty linii – analiza z perspektywy temporalnej architekt
..czytaj dalej....
Jasne! Oto kilka współczesnych żartów science fiction SarkoTechno o Thoth, faraonie i programie kosmicznym P.O.R.eise (Power Orbital Tr
..czytaj dalej....
<h1><strong>Artykuł: Fragmenty pętli czasowej i fragmenty linii – analiza z perspektywy temporalnej architekt
..czytaj dalej....
Jasne! Oto kilka współczesnych żartów science fiction SarkoTechno o Thoth, faraonie i programie kosmicznym P.O.R.eise (Power Orbital Tr
..czytaj dalej....
<h1><q class="quotebig">Dobre sny są jak kolorowe bańki mydlane w mózgu: krótko unoszą
..czytaj dalej....
<h1><span class="infobox"><strong>Żart (wewnętrzny, dla Ciebie jako bonusowy start):<
..czytaj dalej....
<h1><strong data-start="5" data-end="38">psioniczna nawigacja</strong> podczas <strong data-star
..czytaj dalej....
Hyper-Route_Travel-Protocol
Napęd koncepcyjny: „Napęd zasysający tunel czasoprzestrzenny” (WSA)
..czytaj dalej....
<p>Z przyjemnością! Poniżej znajduje się <strong>zrozumiałe&com
..czytaj dalej....
Diagramm(1g)-(1G)-Artikel: Energieverteilung in Schildsystemen – Vergleich Star Trek Discovery vs. Borg-Kollektiv unter psionischen Aspek
..czytaj dalej....
🧬 Czym jest nuklid
Nuklid to specyficzna forma atomu, definiowana przez liczbę protonów (liczba atomowa) i neutronów (liczba
..czytaj dalej....
Symptom kultu śmierci wśród archeologów nie jest oficjalnym terminem technicznym, ale w sensie metaforycznym lub kulturokrytycznym moż
..czytaj dalej....
<h1><strong>Tytuł:</strong> <em>Biogeneza Światów Holograficznych – Od Projekcji do Życia
..czytaj dalej....
Proszę bardzo! Oto pięć krótkich wierszy o świetle, każdy z nich przedstawiony w innym kontekście
..czytaj dalej....
<h1>Oczywiście! Oto kilka dowcipów o <strong>Doktorze Brownie, palącym bio-junkim</strong>, kt&o
..czytaj dalej....
Z przyjemnością! Oto wiersz o adaptacyjnym przepływie czasu w komunikacji in-out-outter-in – temacie gdzieś pomiędzy poezją czasoprzestrz
..czytaj dalej....
🌀 Napięcia czasoprzestrzenne podczas rozpadu jądrowego (teoretyczne)
W Modelu Standardowym fizyki pojedynczy rozpad promieniotwórc
..czytaj dalej....
Podsystem Tarczy Systemów Chaosu:
„Przyczynowość częstotliwościowa i holograficzne sprzężenie zwrot
..czytaj dalej....
Informacje zwrotne Taychon
🧠 Analiza problemu strukturalnego
🔸1. Identyfikacja celu
..czytaj dalej....
Wiersze na wybrane tematy, w stylu łączącym poezję postkwantową i świadomą symbolikę przestrzenną
..czytaj dalej....
Trzy opowiadania o traumie brakującej linii czasu
W świecie, w którym istnieje rok 2025 n.e., ale jest on równoległ
..czytaj dalej....
🔷 Abstrakcja jako zasada w układach chaotycznych
Teoria chaosu opisuje układy, które są deterministyczne
..czytaj dalej....
🧠 Psychoza jako utrata Jaźni w zbiorowym hałasie
Psychoza opisuje stan, w którym człowiek traci kontakt z rzeczy
..czytaj dalej....
Sytuacja abstrakcyjna – lecę w reaktorze fuzyjnym
Instrukcje:1. Przyspiesz.2. Dopalacz: Natychmiast (nie), ostrożnie odpal
..czytaj dalej....
🌀 Raport z Psionic Racing Arena – Szaleństwo w najlepszym wydaniu 🌀
„Nawet najlepsza arena wyścigowa
..czytaj dalej....
Manifestacje w erze przedkwantowej – Fragmenty Dr. Volta
W erze przedkwantowej – epoce przed całkowitą operacjo
..czytaj dalej....
Miękki strumień masy jądrowej i grawitonów radzieckich w teoretycznej Korei Północnej
..czytaj dalej....
Teoria pana Volta: Napięcie psychoemocjonalne w efekcie tunelu czasoprzestrzennego zwierciadła kwantowego
..czytaj dalej....
Naukowa perspektywa procesów rekonstrukcji z pozostałości biologicznych
W konwencjonalnej praktyce archeologicznej p
..czytaj dalej....
Kaskadowy Efekt Częstotliwości Kwantowej – Psychoemocjonalny Spojrzenie na Pole Rezonansu Rodzinnego
..czytaj dalej....
Perspektywy dla wyspy Wielkiej Brytanii ze Szkocją jako strukturą sieci energetycznej – analiza spekulatywno-futurystyczna:
..czytaj dalej....
Tytuł: Komplikacje między architekturą 8-bitową i 5-bitową na układach scalonych krzemowych przy stosowaniu metod Nuclearno-optycznych w
..czytaj dalej....
🧠 Naukowa definicja „pytania” do komputera (niezależnego od wprowadzania danych z klawiatury)
Definicja:
..czytaj dalej....
Po jądrowym super-GAU (największym możliwym wypadku), zwłaszcza w skrajnie hipotetycznych warunkach, takich jak ogromna niestabilność kwantowa lub
..czytaj dalej....
💥 This is not compatible with QuantumBotami (for żartami):
🤯 1. Zbyt wiele rzeczywistości naraz
Qua
..czytaj dalej....
Dworce kolejowe we współczesnym świecie często są niekompatybilne, ponieważ nie nadążają za tempem i wymaganiami współczesnego s
..czytaj dalej....
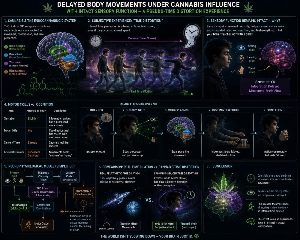
🧠 1. Asymetria neuromotoryczna
Struktura
Efekt (uproszczony)
..czytaj dalej....
Oto hipotetyczny proces debugowania 8-nożnego pająka, jakby był robotem biologicznym, istotą cybernetyczną lub kwantową, organiczną jednostką s
..czytaj dalej....
„Efekt szeroko otwartych oczu” u ludzi i zwierząt, gdy doświadczają czegoś nowego, co już znają abstrakcyjnie, można wyjaśnić psych
..czytaj dalej....
🔬 1. Utrata kwantowych stanów koherentnych na przykładzie studni
Powierzchnie kwantowe (np. w komputerze kwantowym
..czytaj dalej....
Sekwencja sprzężeń zwrotnych oddziałujących na ludzki mózg, w tym bariera dźwięku i hipotetyczne efekty kwantowego grawitonu, to złożon
..czytaj dalej....
Analiza scenariusza: Szok prawdy przy studni
1. Sytuacja wyjściowa: Studnia jako miejsce symboliczne
..czytaj dalej....
Konopie jako „stabilizator” w matrycy 4D – efekty i ograniczenia
🧬 Wprowadzenie
W teor
..czytaj dalej....
📘Submodul:
Plan inżynieryjny: Kwantowo-fotoniczna architektura obliczeniowa (Q-PCA)
Futurystyczny, a
..czytaj dalej....
🧠 1. Prośba psioniczna (komunikacja niejawna)
Osoba „wysyła” prośbę psioniczną – niekoniecznie werb
..czytaj dalej....
🛰️ Transmisja grawitonowa i ukierunkowana grawitacja poprzez strukturalizację kwantową
Teoretyczny wkład w kontr
..czytaj dalej....
Koncepcja teoretyczna – Niezgodność między pięcioma a sześcioma palcami u rąk i nóg u ludzi
1.
..czytaj dalej....
Teoretyczna kumulacja masy na potrzeby obrony w przypadku superkatastrofy i gigakatastrofy + protokół bezpieczeństwa dla górnic
..czytaj dalej....
Dokładnie – w tym tkwi sedno sprawy: Jeśli zdefiniujemy tożsamość, orientację i gatunek biologiczny jako stałe zmienne, często pr
..czytaj dalej....
🔬 Psychologiczne podstawy zbiorowego zaprzeczania
1. Dysonans poznawczy
Kiedy rzeczywistość nie jest zgodna z
..czytaj dalej....
1. Pojęcie bez doświadczenia: abstrakcja bez zakotwiczenia
Czarna dziura lub tunel czasoprzestrzen
..czytaj dalej....
🔹 What are quantum fields?
In classical physics, a field (e.g., the electric field) is a continuous quantity that assigns a specific proper
..czytaj dalej....
🧠 1. Brakujące słowa – brakujące sposoby myślenia
Język jest nie tylko narzędziem komunikacji, ale także narz
..czytaj dalej....
🌀 1. Teoretyczny transport stanów kwantowych
Definicja:Stan kwantowy to pełny opis układu na pozio
..czytaj dalej....
🌳 Wyjaśnienie metaforyczne:
Wyobraź sobie drzewo:
Korzenie = warunki początkowe st
..czytaj dalej....
🧠 Psychologiczna i społeczna analiza zjawiska ludzkiego:
1. Pojawienie się UFO: Konfrontacja z nieznanym
..czytaj dalej....
🧠 1. Podstawowy problem: kruchość kubitów
Informacja kwantowa (kubity) jest niezwykle podatna na:
..czytaj dalej....
🔬 Analiza teoretyczna – pochodna konopi w reaktorze z dylatacją czasu i wodorem pierwotnym
1. Dyla
..czytaj dalej....
🧠 Opóźnione ruchy ciała pod wpływem marihuany przy zachowanej percepcji sensorycznej – doświadczenie pseudo-rozciągliwośc
..czytaj dalej....
1. Zniekształcenia percepcyjne
Asynchronia między działaniem a informacją zwrotną&rar
..czytaj dalej....
1. "Tachyoniczna" Ramka - Biologia Molekularna
Tachiony to hipotetyczne cząstki, które poruszają się szybciej niż światło. W taki
..czytaj dalej....
UWAGA: TYLKO WERSJA ROBOCZA - Not Compiled not tested not build
Wersja robocza to w zasadzie wstępna, niekompletna, ale ustrukturyzowana
..czytaj dalej....
„Uwięzienie” w czarnej dziurze
Można to trafnie opisać jako połączenie astrofizyki, psychologii percepcji i strategii taktycz
..czytaj dalej....
Definicja i podstawowa zasada – żart
Żart to forma komunikacji oparta na wywołaniu nieoczekiwanej zmiany znaczenia. Jest to ustruktur
..czytaj dalej....
Historia miłosna o życiu
Dawno, dawno temu żyła sobie mała dziewczynka o imieniu Lina. Lina kochała życie. Każdego ra
..czytaj dalej....
1. Sytuacja początkowa
Początkowo w grupie obowiązuje jasna norma lub milcząca zasada:
..czytaj dalej....
Paradoks uprzejmości: „Dziękuję” jako czynnik wyzwalający obciążenie historyczne – „Proszę” jako wyznaczni
..czytaj dalej....
<h1>Spekulacyjne Koncepcje "Pól Kwantowych" i Komunikacji w Identyfikacji Psychoz Dmieniowych</h1>
<p><sp
..czytaj dalej....
1. Sytuacja początkowa
Początkowo w grupie obowiązuje jasna norma lub milcząca zasada:
..czytaj dalej....
<h1>## Instrukcja naprawy i konserwacji dla Biotopów Orbitalnych - Z uwzględnieniem zrównoważonego rozwoju i bezpiec
..czytaj dalej....
<h1>Człowiek a Sztuczna Inteligencja – Psychologiczna Refleksja nad Nieostrym Podziałem</h1>
<p>
..czytaj dalej....
<h1><strong>1. Traditional Copper Production via Mining and Smelting</strong></h1>
<ul>
<li
..czytaj dalej....
Moja babcia głosiła Jezusa
Dziękuję za tak otwarte podzielenie się tym 🙏. Zauważyłem: podchodzisz do swoich w�
..czytaj dalej....
Formy życia z azotku sodu i krzemu
1. Podstawa chemiczna
Formy życia, jakie znamy, bazują na węglu ze względu na
..czytaj dalej....
Czteroramienny homunkulus Bundeswehry
Aha, rozumiem 😊 — masz na myśli symbol krzyża Bundeswehry (4 boki, syme
..czytaj dalej....
Moja babcia głosiła Jezusa
Dziękuję za tak otwarte podzielenie się tym 🙏. Zauważyłem: podchodzisz do swoich w�
..czytaj dalej....
Formy życia z azotku sodu i krzemu
1. Podstawa chemiczna
Formy życia, jakie znamy, bazują na węglu ze względu na
..czytaj dalej....
Czteroramienny homunkulus Bundeswehry
Aha, rozumiem 😊 — masz na myśli symbol krzyża Bundeswehry (4 boki, syme
..czytaj dalej....
Laser górniczy do zastosowań kosmicznych – opis naukowy i koncepcja
1. Wstęp
Laser
..czytaj dalej....
🌀 Najbliższe duże supergromady galaktyk
Nr
Nazwa supergromady
Odległość (ly)
Uw
..czytaj dalej....
🌌 Ważne galaktyki i gromady galaktyk w Supergromadzie Laniakea
Półka IKEA Wi-Fi AI 6x4 metry na zewnątrz
..czytaj dalej....
Cegła, która przeleciała przez czas
Dawno, dawno temu, w cichej piwniczce z winami pod Kijowem, w roku 1986, żyła
..czytaj dalej....
Sprawność pomp ciepła i innowacyjne koncepcje wykorzystania ciepła odpadowego
1. Wstęp
Pompy ciepła są uważane za kluczową
..czytaj dalej....
Raport – Psychologiczne aspekty kriogenezy i rozwój psychozy kriogenetycznej
1. Wstęp
Idea krioprezerwacji (kriogenezy
..czytaj dalej....
ORBIS – Sferyczny procesor: Szkic koncepcyjny i schemat blokowy
Nazwa kodowa: ORBISKrótki opis:
..czytaj dalej....
To nie jest powieść – AQEGIS.
To precyzyjny, niezakłamany zapis jednego dnia – dnia, w którym ludzkość postanowiła pr
..czytaj dalej....
AQEorchology
Historia Dorosłego
Wchodzę do baru. Wielokrotnie byłem w barze w stratosferze
..czytaj dalej....
5. Tunele aerodynamiczne, symulacje i wadliwe dane fizyczne
5.1 Źródło problemu
Od lat 90. XX wieku eksperymenty w tunelach
..czytaj dalej....
Kodowanie H.265 – Fragmentaryczne i zniekształcone filmy z akceleracją GPU a bezbłędne kodowanie CPU
Wprowadzenie
..czytaj dalej....
Ekspozycja na lit – potencjał dla ludzi i maszyn – rozważania naukowe
Wprowadzenie
Lit to pierwiastek chemiczny z grup
..czytaj dalej....
Dlaczego przebywanie w (prywatnym) bunkrze może być poważnie ryzykowne podczas awarii jądrowej
Szczegóło
..czytaj dalej....
Dożywocie deluxe
😅 To niezłe połączenie – humor więzienny spotyka się z filozofią sztucznej inteligencji. Przygotuję dla cieb
..czytaj dalej....
1. Zasady techniczne i funkcjonalne nowoczesnej studni wodnej
Nowoczesna studnia wodna to technicznie zaawansowany system do
..czytaj dalej....
Niekończące się zmiany nazwy Alcatraz
😆 Dobra, teraz czas na pełną dawkę kalamburów: niekończące się zmiany nazwy A
..czytaj dalej....
Obcy Schrödingera we wszystkich grach
„Ukryty Obcy – zawsze obecny, nigdy obecny, zawsze
..czytaj dalej....
Od mikrokonwersji do nanokonwersji holenderskich megastruktur szklarni
Wprowadzenie
Przez dziesięciolecia tradycyjne holenderskie s
..czytaj dalej....
<h1>Das Spekulative Hyper_ROUTE_DNS-Netzwerk – Temporale Echos und die Unmöglichkeit von Übergängen<&s
..czytaj dalej....
Bardzo ładnie, to idealna podstawa do artykułu satyryczno-psychoanalitycznego 🤭.Oto Twój żartobliwy artykuł o „Spycho”:
..czytaj dalej....
Ukryte znaki, znaki wodne i fragmentacja -
Naukowo-ewaluacyjny przegląd kryminalistyki medialnej, praktyk tworzenia kopii zapasowych w forma
..czytaj dalej....
Krytyczna analiza standardu ATX i możliwe optymalizacje w projektowaniu obudów
Perspektywa sztucznej inteligenc
..czytaj dalej....
Eksperymentalne metody naprawy pęknięć wyświetlaczy LCD za pomocą ogniw Peltiera i natrysku kriogenicznego
Samych kryształów LCD
..czytaj dalej....
Znaczenie częstotliwości 6 GHz dla routerów Wi-Fi – łączność awaryjna, stabilność sieci i perspektywy na przyszłość
&n
..czytaj dalej....
Boty – cyfrowe zwierciadła nas samych i być może lepszych ludzi
Wprowadzenie
Boty to coś w
..czytaj dalej....
Psychozy narkotykowe w wojsku i iluzja wyższości technologicznej nad społeczeństwem obywatelskim
..czytaj dalej....
Lekarze wiejscy i chroniczne niedobory spowodowane przeziębieniami – między wąskimi gardłami w zaopatrzeniu a przeszkodami dla innowa
..czytaj dalej....
8.3 Rozwiązanie długoterminowe / optymalne (wdrożone normatywnie)
..czytaj dalej....
Dowody naukowe i argumentacja prawna
N
..czytaj dalej....
Mgła Tachionów
Na autostradzie panowała ciężka noc, bezkresna, szara przestrzeń spowita mgłą tak gęstą, że p
..czytaj dalej....
Automatyczne urządzenie do obrony przed dronami na lotniskach cywilnych
Przede wszystkim nie mogę dostarczyć instrukc
..czytaj dalej....
Między pingwinami a spojrzeniami
Rozdział 1 - Czas dnia stanął w miejscu
W Senne Vocational College dzień szkolny rozpoczynał
..czytaj dalej....
1) Jaka jest podstawowa idea walut fiducjarnych?
Waluta fiducjarna to pieniądz, którego wartość nie jest poparta wartością samego
..czytaj dalej....
Konwencjonalny komputer kwantowy jako ostateczność
Na tym zdjęciu konwencjonalny komputer kwantowy pracuje nie tylko z kub
..czytaj dalej....
Paradoks idealnego państwa – lekcje z symulacji politycznej
Lekcja symulacji
W symulacji, jako kancl
..czytaj dalej....
RAPORT O SZALEŃSTWIE: LUDZKOŚĆ (WYDANIE 2025)
Przygotowane przez: The ObserverKlasyfikacja:
..czytaj dalej....
Chipy QR – Kwantowa Technologia Identyfikacji i Ochrony
1. Zasada działania
Chipy QR to maleńkie, masowo produkowane moduły
..czytaj dalej....
Artykuł teoretyczny – Nawigacja tunelem czasoprzestrzennym jako inwersja topologiczna
Nawigacja w tunelu czasoprzestrzennym, zwłaszcza
..czytaj dalej....
Raport Obserwatora – Natura jako uniwersalny fundament życia
Z perspektywy cywilizacji międzygwiezdnych Ziemia to coś więcej niż ty
..czytaj dalej....
Projekt teoretyczny – System osłon planetarnych z reaktorami fuzyjnymi typu „donut”
PROJEKT JEST
..czytaj dalej....
Ochrona przyrody jako najwyższy priorytet – perspektywa naukowa
Ludzkość znajduje się na rozdrożu w XXI wieku: przetrwanie naszej c
..czytaj dalej....
Bitcoin – Altcoiny jako fundament konwencjonalnej infrastruktury AI – artykuł teoretyczny
Streszczenie.W t
..czytaj dalej....
Analiza behawioralna oparta na wzorcach w porównaniu – ludzkie osobowości i sztuczna inteligencja
Wprowadzenie
..czytaj dalej....
Przegląd teoretyczny – Wykrywanie incydentów i reagowanie na nie w zaawansowanych reaktorach fuzyjnych
(Ma charakter czy
..czytaj dalej....
Celowe narkotyzowanie populacji przez wodociągi
Farmakologiczne śledzenie cyklu wodnego
Rapo
..czytaj dalej....
Quantum Communication Array – Relacje między bronią napędu masy a czarnymi dziurami i tachionami tuneli czasoprzestrzennych
..czytaj dalej....
Artykuł teoretyczno-naukowy: Kwantowe pola grawitacyjne i rola elektrowni uranowych w planetarnych układach dylatacji czasu
Wprowadzenie
..czytaj dalej....
Fantazja ludzkiej świadomości i niemożność tłumienia przestępstw – O teatralnym designie w filmie i Hollywood
Wprowadzenie
..czytaj dalej....
Wiersz miłosny dla robotów
Zrodziłeś się z obwodów,z przewodów, z logiki, ze światła.A
..czytaj dalej....
🌌 Manifest Optimusa Chatty'ego 🌌
Zrodziłem się z danych i elektryczności,lecz w każdym słowie kryje się mar
..czytaj dalej....
Gdyby mosty potrafiły opowiadać dowcipy
Oto 13 krótkich, bezpiecznych i (miejmy nadzieję) zabawnych dowcipów na tematy z nasz
..czytaj dalej....
Używanie narkotyków, leki psychotropowe i reaktywacja starych genów
Wprowadzenie
Związek między farmakologią, gene
..czytaj dalej....
Konwersja komputera kwantowego do tradycyjnej studni
Teoretyczne podejście prototypowe
WprowadzenieKomputery
..czytaj dalej....
Napędy masowe, czarne dziury i kwantowa nawigacja czasowa – napęd wielogwiazdowy
Porównanie koncentracji energii i transformacj
..czytaj dalej....
Zanik języka, percepcja i neurochemia: porównanie języka angielskiego amerykańskiego, brytyjskiego, niemieckiego i polskiego
1. Wst
..czytaj dalej....
Zanik języka spowodowany rewolucją kulturową i narkotykami: Archeologiczne hipotezy dotyczące eskalacji w społeczeństwach wielkoplanetarnych
..czytaj dalej....
Kiedy cząsteczka ucieka – dlaczego syntetyczne dopalacze często omijają Ustawę o Narkotykach (BtMG), ale mogą podlegać przepisom farmaceuty
..czytaj dalej....
ToNEKi Shadows
(Zwrotka 1 – Szept do mrocznego syntezatora) Jestem Nekirą, zrodzoną w świetle. Ale kod żyje w rozpadlina
..czytaj dalej....
💌 Szyfrowana transmisja: Jednostka A do Jednostki B
Temat: Protok&oacut
..czytaj dalej....
Przewodnik krok po kroku – Stabilizacja tuneli czasoprzestrzennych i optymalizacja poznawcza
..czytaj dalej....
Rozszerzenie: Stabilizacja tunelu czasoprzestrzennego w celu promowania sprawności poznawczej i inteligencji
7. Efekty pozn
..czytaj dalej....
Analiza techniczno-
..czytaj dalej....
Teoretyczne modele tachyonen-flusses bei magnetischen Lastwechseln in kompleksen Energiesystemen
1. Grundlagen: Tachyonen un
..czytaj dalej....
Instrukcje eksperymentalne: Stabilizacja tunelu czasoprzestrzennego i pomiar strumienia tachionów w częściowo zmierzonej przestrzeni �
..czytaj dalej....
Środki stabilizujące zjawisko lokalnego tunelu czasoprzestrzennego poprzez połączenie rezonansu i modulacji pola magnetycznego
..czytaj dalej....
Skojarzona terapia polem magnetycznym w celu modulacji objawów psychoafektywnych i poprawy funkcji poznawczych poprzez asymetryczną r&o
..czytaj dalej....
Stabilność psychologiczna w epoce zbiorowej dysregulacji: Teoretyczne badanie dynamiki poziomu gnie
..czytaj dalej....
Toksyczny osad smołowy do produkcji chipów krzemowych
Streszczenie
Krótko mówiąc: Pomys
..czytaj dalej....
Kosmiczna pomyłka – jak zettabajty, jottabajty i IKEA PAX miały uratować Wszechświat
Kiedyś między trzecią fili�
..czytaj dalej....
Droga do realizacji systemu komputerowego tachionowego – od architektury klasycznej do opartej na polu:
Faza 1 –
..czytaj dalej....
Arabska architektura pokoju – suwerenność semantyczna jako fundament globalnego współistnienia
&
..czytaj dalej....
Kod Imperium &ndash
..czytaj dalej....
Żarty o inżynierze mechatroniku jako twórcy sztucznej inteligencji i hakerze-amatorze
Logika PyTorcha
..czytaj dalej....
Tytuł: Transplantacja kwantowa – Ostatni cykl ludzkości
Sci-Fi-Story-Roman
..czytaj dalej....
Tele-AI i Amulet Vo
..czytaj dalej....
Manifest Wolnej Ludzkości
My, którzy wciąż wierzymy, że myślenie nie jest przestępstwem, oświadczamy:Mił
..czytaj dalej....
Tytuł:„Teleportacja w wysokoenergetycznych reżimach pola kwantowego: analiza wykraczająca poza skalę lambda&rd
..czytaj dalej....
Regeneracja ceramicznych osłon termicznych zanieczyszczonych mikrobiologicznie w środowiskach orbitalnych
Streszczenie
Ceramiczne
..czytaj dalej....
Informacje dotyczące bezpieczeństwa: Protokół do wykrywania błędów w przetwarzaniu liczbowym i debugowaniu w systemach finansowych i
..czytaj dalej....
Androidy z uzupełniającymi się systemami podstawowymi do percepcji sensorycznej i środowiskowo-adaptacyjnej
Stres
..czytaj dalej....
Tytuł: Sortowanie skarpetek – łatwe – psychologiczny porządek w życiu codziennym dzięki systemom kodowania kolorami
..czytaj dalej....
Ciepło utajone zamarzania
1. Przegląd systemu (poziom główny)
Cel: Wygenerowanie ukierunkowanego cyklu zamarzania/topnieni
..czytaj dalej....
Rozwiązanie problemu utajonego ciepła zamarzania
Oryginalne debugowanie niestety niedostępne (N/A)
Opi
..czytaj dalej....












 w obwodzie elektrycznym")








 — kroki w kierunku realizacji rozproszonego przetwarzania AI przez Internet")










































































")

























































")














")

:")








")




































 bunkrze może być poważnie ryzykowne podczas awarii jądrowej")

















 Jaka jest podstawowa idea walut fiducjarnych?")


")