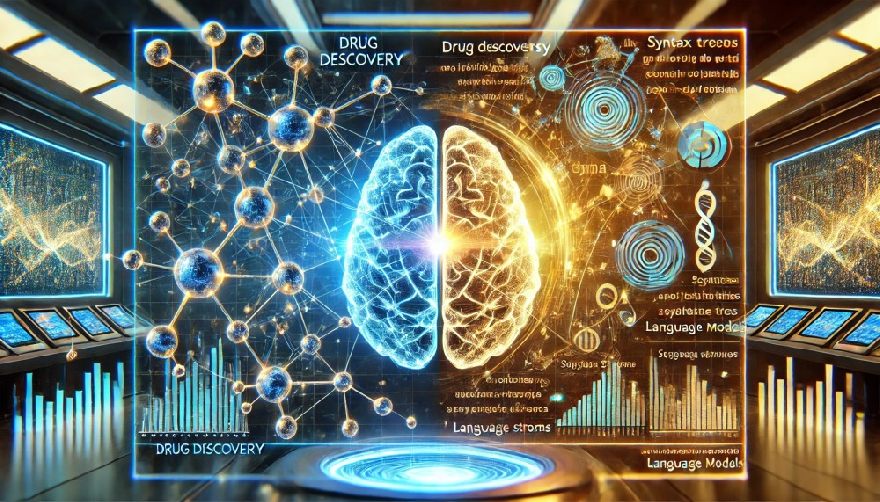
Aplicación de técnicas de IA desde el descubrimiento de fármacos hasta los LLM para reducir las alucinaciones
5 de diciembre de 2024
Proyectos revolucionarios de GitHub: Descubrimiento automatizado de fármacos con IA La integración de la inteligencia artificial (IA) en el descubrimiento de fármacos está revolucionando la industria farmacéutica. Los proyectos de código abierto en GitHub desempeñan un papel crucial en este proceso. A continuación, presentamos algunos de los proyectos más innovadores que impulsan el descubrimiento automatizado de fármacos mediante IA. DeepChem: Plataforma abierta para el aprendizaje profundo en química DeepChem es una biblioteca líder de código abierto que facilita el acceso al aprendizaje profundo para aplicaciones químicas. Proporciona herramientas para:
- Modelado molecular
- Predicción de la estructura de proteínas
- Ciencia de los materiales
A través de su interfaz intuitiva, DeepChem permite a los investigadores implementar modelos complejos de IA sin necesidad de conocimientos profundos de programación. Esto acelera el descubrimiento de nuevos fármacos y promueve la innovación en la industria.
MoleculeNet: Benchmarking para IA en Química
MoleculeNet es un sistema integral de benchmarking diseñado específicamente para el aprendizaje automático en la investigación química. Ofrece:
- Conjuntos de datos estandarizados
- Métricas de evaluación
- Comparación del rendimiento del modelo
Al proporcionar puntos de referencia consistentes, MoleculeNet facilita la comparación de diferentes modelos de IA, impulsando así el progreso en el descubrimiento de fármacos.
ATOM Modeling PipeLine (AMPL): Descubrimiento acelerado de fármacos
ATOM Modeling PipeLine es un proyecto del Consorcio ATOM que busca acelerar el desarrollo de fármacos mediante el aprendizaje automático. AMPL ofrece:
- Proceso modular para la preparación de datos
- Entrenamiento automatizado de modelos
- Marcos extensibles para diversos casos de uso
Con AMPL, los investigadores pueden construir modelos complejos de forma eficiente, acortando así el tiempo desde el descubrimiento hasta la comercialización de nuevos fármacos.
Chemprop: Predicción de propiedades moleculares con aprendizaje profundo
Chemprop utiliza redes neuronales de grafos para predecir propiedades moleculares. Sus características incluyen:
- Alta precisión de predicción
- Arquitecturas de modelos adaptables
- Compatibilidad con diversos conjuntos de datos químicos
Chemprop ha obtenido resultados sobresalientes en varias competiciones y es una herramienta valiosa para la química asistida por IA.
DeepPurpose: Kit de herramientas universal para el descubrimiento de fármacos
DeepPurpose es un completo kit de herramientas de aprendizaje profundo para el descubrimiento de fármacos. Ofrece:
- Integración de diversos modelos y conjuntos de datos
- Fácil implementación de modelos predictivos
- Aplicaciones en interacciones proteína-ligando
Gracias a su versatilidad, DeepPurpose permite a los investigadores identificar nuevos candidatos terapéuticos de forma rápida y eficiente.
OpenChem: Marco de aprendizaje profundo dedicado a aplicaciones químicas
OpenChem es un marco de aprendizaje profundo adaptado a la química. Incluye:
- Soporte para la generación de moléculas
- Predicción de propiedades
- Flexibilidad en el diseño de modelos
OpenChem promueve el desarrollo de nuevos métodos en IA química y contribuye a acelerar la investigación.
La comunidad de código abierto en GitHub está ampliando los límites del descubrimiento automatizado de fármacos con estos proyectos. La combinación de IA y química abre nuevas posibilidades para desarrollar soluciones terapéuticas de forma más eficiente y precisa. Estas innovaciones tienen el potencial de cambiar el futuro de la medicina de forma sostenible.
Aplicación de modelos de investigación de IA desde el descubrimiento de fármacos hasta la síntesis de modelos de IA
ElLos modelos y métodos de IA utilizados ofrecen enfoques innovadores que pueden transferirse a la destilación de modelos de IA. Aunque ambos campos parecen diferentes a primera vista, comparten técnicas y desafíos comunes que permiten una aplicación significativa.
Sentido de la aplicación
La aplicación de modelos de investigación, desde el descubrimiento de fármacos hasta la destilación de modelos de IA, tiene sentido porque:
- Métodos comunes: Ambos campos utilizan técnicas avanzadas de aprendizaje automático, como el aprendizaje profundo, las redes neuronales y los modelos basados en grafos.
- Reducción de la complejidad: En el descubrimiento de fármacos, las estructuras moleculares complejas se representan de forma simplificada, similar a la reducción de grandes modelos de IA a formas más compactas.
- Optimización y eficiencia: Tanto el descubrimiento de fármacos como la destilación de modelos buscan lograr resultados eficientes y eficaces con recursos limitados.
Cómo se puede aplicar
1. Redes Neuronales Graficas (GNN) para la Comprensión Estructural
En la investigación farmacológica, las Redes Neuronales Graficas se utilizan para analizar estructuras moleculares. Estas técnicas pueden emplearse en la destilación de modelos para comprender la estructura de modelos grandes y extraer características esenciales para el modelo más pequeño.
2. Aprendizaje por Transferencia y Extracción de Características
Los modelos de proyectos como DeepChem o Chemprop utilizan el aprendizaje por transferencia para aprender de conjuntos de datos existentes. De igual forma, en la destilación, un modelo grande preentrenado puede servir como punto de partida para transferir características esenciales al modelo más pequeño.
3. Aprendizaje Multitarea para Modelos Versátiles
Proyectos como MoleculeNet utilizan el aprendizaje multitarea para entrenar modelos que puedan gestionar múltiples tareas simultáneamente. Este método se puede utilizar en la destilación para crear modelos compactos que, a la vez, realizan funciones versátiles.
4. Técnicas de optimización a partir del descubrimiento de fármacos
Los enfoques de optimización a partir del descubrimiento de fármacos, como el ajuste fino de hiperparámetros o el uso de algoritmos evolutivos, se pueden aplicar para aumentar la eficiencia de los modelos destilados.
5. Aumento y generación de datos
La generación de datos sintéticos es clave en proyectos como DeepPurpose. Se pueden utilizar técnicas similares para mejorar el proceso de entrenamiento del modelo del estudiante en la destilación, especialmente cuando la disponibilidad de datos es limitada.
Pasos prácticos de implementación
- Análisis de la estructura del modelo: Uso de redes neuronales genómicas (GNN) para identificar componentes importantes del modelo del profesor.
- Selección de características: Extracción de características críticas para el rendimiento del modelo.
- Diseños de arquitectura eficientes: Adaptación de las arquitecturas de modelos del descubrimiento de fármacos para estructuras de modelos más compactas.
- Entrenamiento conjunto: Implementación del aprendizaje multitarea para entrenar al modelo del estudiante en múltiples tareas y, por lo tanto, mejorar la capacidad de generalización.
La integración de métodos del descubrimiento automatizado de fármacos en la destilación de modelos de IA abre nuevas vías para aumentar la eficiencia y reducir la complejidad. Mediante la transferencia de técnicas probadas, se pueden desarrollar modelos potentes y compactos que cumplen con los requisitos de las aplicaciones modernas de IA. Este enfoque interdisciplinario promueve la innovación y acelera el progreso en ambos campos de investigación.
Extensión: Aplicación de técnicas de IA desde el descubrimiento de fármacos hasta los LLM para reducir las alucinaciones
Los avances en inteligencia artificial han revolucionado tanto el descubrimiento de fármacos como el desarrollo de grandes modelos lingüísticos (LLM). Una pregunta interesante es si las técnicas del descubrimiento automatizado de fármacos pueden ayudar a aumentar la precisión de la predicción de los LLM y reducir las alucinaciones. A continuación, exploramos esta posibilidad y analizamos si dicha aplicación es útil y si estas técnicas ya se utilizan en los LLM.
Conexión entre IA y tecnologíaTécnicas en Química y Maestrías en Derecho (LLM)
1. Redes Neuronales Graficas (GNN) y Análisis Estructural
En el descubrimiento de fármacos, las Redes Neuronales Graficas se utilizan para comprender y predecir las estructuras complejas de las moléculas. Las GNN modelan los datos como grafos, lo cual es natural en química porque las moléculas constan de átomos (nodos) y enlaces (aristas).
Aplicación a las LLM:
- Árboles sintácticos como grafos: Al igual que las moléculas, las oraciones se pueden representar como grafos, donde las palabras son nodos y las relaciones gramaticales son aristas.
- Modelado de contexto mejorado: Las GNN podrían utilizarse para modelar mejor las relaciones entre las palabras de una oración, lo que podría mejorar la contextualización en las LLM.
2. Incertidumbre y estimación de la incertidumbre
En el descubrimiento de fármacos, la estimación de la incertidumbre es crucial para evaluar la fiabilidad de las predicciones.
Aplicación a los LLM:
- Reducción de las alucinaciones: Al incorporar estimaciones de la incertidumbre, los LLM podrían evaluar mejor sus propias predicciones y ser menos propensos a proporcionar información falsa o alucinada.
- Métricas de confianza: Implementar métricas que indiquen la confianza del modelo en su respuesta.
3. Aprendizaje multitarea y aprendizaje por transferencia
Proyectos como MoleculeNet utilizan el aprendizaje multitarea para entrenar modelos que predicen múltiples propiedades simultáneamente.
Aplicación a los LLM:
- Optimización simultánea de múltiples objetivos: Los LLM podrían entrenarse para optimizar tanto la predicción de la siguiente palabra como la precisión del contenido.
- Transferencia de conocimiento del dominio: Mediante el aprendizaje por transferencia, los modelos pueden utilizar conocimientos específicos de la química para realizar predicciones más precisas en ese dominio.
4. Aumento de datos y generación de datos sintéticos
En química, los datos sintéticos se utilizan para mejorar los modelos, especialmente cuando los datos reales son limitados.
Aplicación a los LLM:
- Ampliación de los conjuntos de datos de entrenamiento: Generación de datos de texto adicionales de alta calidad para mejorar el proceso de entrenamiento.
- Mejora de la capacidad de generalización: Con datos más diversos, el modelo puede generalizar mejor y generar menos alucinaciones.
¿Tiene sentido esta aplicación?
Transferir técnicas del descubrimiento de fármacos asistido por IA a los LLM tiene sentido teórico, ya que ambos campos utilizan estructuras de datos complejas y aprendizaje automático. Algunas razones son:
- Fundamentos matemáticos comunes: Ambos campos utilizan redes neuronales y métodos de optimización.
- Necesidad de precisión y fiabilidad: Tanto en medicina como en el procesamiento de la información, las predicciones precisas son cruciales.
Desafíos
- Diferentes tipos de datos: Los datos químicos son estructuralmente diferentes del lenguaje natural.
- Escalabilidad: Los modelos de aprendizaje de larga duración (LLM) suelen ser significativamente más grandes y complejos que los modelos en química, lo que dificulta su aplicación directa.
¿Ya se utilizan estas técnicas en los LLM?
Muchas de las técnicas mencionadas ya se utilizan de alguna forma en los LLM. Integrado:
- Estimación de la incertidumbre: Algunos modelos utilizan enfoques bayesianos o el método de Monte Carlo para modelar. Incertidumbre.
- Modelos basados en grafos: Si bien las redes neuronales de gramática (GNN) no se utilizan directamente en los LLM, existen modelos que consideran árboles sintácticos o grafos de dependencia.
- Aprendizaje multitarea y por transferencia: Los LLM como GPT-4 utilizan el aprendizaje por transferencia y pueden ajustarse para múltiples tareas.
Posibles enfoques innovadores
A pesar de las técnicas existentes, existe potencial para nuevos enfoques:
- Modelos híbridos: Combinación de LLM con GNN para un mejor modelado del contexto.
- Optimización inspirada en la química: Uso de métodos de optimización de la química para mejorarDesarrollo de procedimientos de formación en LLM.
- Conjuntos de datos interdisciplinarios: Incorporación de datos de química para aumentar la precisión de los LLM en áreas especializadas.
La aplicación de técnicas del descubrimiento automatizado de fármacos a los LLM ofrece oportunidades interesantes para mejorar la precisión de las predicciones y reducir las alucinaciones. Si bien algunos métodos ya se utilizan en los LLM, existe margen para una mayor innovación mediante un enfoque interdisciplinario. Los desafíos residen principalmente en los diferentes tipos de datos y la escalabilidad. Sin embargo, la colaboración entre estos dos campos podría conducir a avances significativos en la investigación de IA.
Experimento mental breve: ¿Tiene sentido?
La química y el lenguaje natural parecen diferentes a primera vista, pero ambos son sistemas con reglas y estructuras complejas. Por lo tanto, las técnicas de modelado y predicción en química podrían proporcionar información valiosa para el procesamiento del lenguaje natural. Es importante estar abierto a enfoques interdisciplinarios, ya que la innovación suele surgir en las interfaces de diferentes disciplinas.
Integrar técnicas de IA, desde el descubrimiento de fármacos hasta el desarrollo de modelos de lenguaje de larga duración (LLM), podría ser una forma prometedora de mejorar aún más el rendimiento de estos modelos. Al aprender mutuamente, ambos campos pueden beneficiarse mutuamente y abrir conjuntamente nuevos horizontes en la investigación de IA.
Implementación para reducir las alucinaciones en LLM usando Hugging Face
A continuación, demostramos cómo crear un modelo de lenguaje con estimación de incertidumbre usando Hugging Face y Python para reducir las alucinaciones. Utilizamos técnicas inspiradas en los métodos empleados en el descubrimiento automatizado de fármacos, en particular la estimación de la incertidumbre mediante el método de Monte Carlo Dropout.
Requisitos
- Python 3.6 o superior
- Bibliotecas instaladas:
transformerstorchdatasets
Puede instalar las bibliotecas necesarias con el siguiente comando:
pip install transformers torch datasets
Implementación del código
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch.nn.functional as F
import numpy as np
# Cargar el tokenizador y el modelo
model_name = 'gpt2'
tokenizador = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
# Habilitar la deserción incluso en modo de evaluación
def enable_dropout(model):
""Habilita las capas de deserción en el modelo durante la evaluación."""
for module in model.modules():
if isinstance(module, torch.nn.Dropout):
module.train()
# Función para la generación con estimación de incertidumbre
def generate_with_uncertainty(model, tokenizer, prompt, num_samples=5, max_length=50):
model.eval()
enable_dropout(model)
inputs = tokenizer(prompt, return_tensors='pt')
input_ids = inputs['input_ids']
# Múltiples predicciones para la estimación de incertidumbre
outputs = []
para _ en rango(num_muestras):
con torch.no_grad():
salida = model.generate(
id_entrada=id_entrada,
longitud_máxima=longitud_máxima,
do_sample=True,
top_k=50,
top_p=0.95
)
salidas.append(salida)
# Decodificación de las secuencias generadas
sequences = [tokenizer.decode(salida[0], skip_special_tokens=True) para la salida en salidas]
# Cálculo de la incertidumbre (entropía)
probs = []
para la salida en salidas:
con torch.no_grad():
logits = model(salida)['logits']
prob = F.softmax(logits, dim=-1)
prob.append(prob.cpu().numpy())
# Cálculo de la entropía promedio
entropies = []
para prob en Probabilidades:
entropía = -np.suma(prob * np.log(prob + 1e-8)) / prob.tamaño
entropías.append(entropía)
entropía_promedio = np.media(entropías)
incertidumbre = entropía_promedio
# Selección de la secuencia más frecuente
from collections import Counter
conteos_secuencia = Contador(secuencias)
secuencia_más_común = conteos_secuencia.más_común(1)[0][0]
return {
'texto_generado': secuencia_más_común,
'incertidumbre': incertidumbre
}
# Ejemplo de uso
prompt = "El impacto de la inteligencia artificial en la medicina es"
resultado = generate_with_uncertainty(modelo, tokenizador, mensaje)
print("Texto generado:")
print(resultado['texto_generado'])
print("Incertidumbre estimada:", resultado['incertidumbre'])
Explicación del código
-
Carga del modelo y el tokenizador: Usamos el modelo GPT-2 preentrenado de Hugging Face.
tokenizador = AutoTokenizer.from_pretrained(nombre_del_modelo)
model = AutoModelForCausalLM.from_pretrained(nombre_del_modelo)
-
Habilitar la omisión: Usamos la función enable_dropout para habilitar las capas de omisión. Durante la evaluación para habilitar la deserción de Monte Carlo.
def enable_dropout(model):
for module in model.modules():
if isinstance(module, torch.nn.Dropout):
module.train()
-
Generación con estimación de incertidumbre: La función generate_with_uncertainty realiza múltiples predicciones y calcula la incertidumbre basándose en la entropía de las distribuciones de salida.
def generate_with_uncertainty(model, tokenizer, prompt, num_samples=5, max_length=50):
# Función implementada como se muestra arriba
-
Cálculo de la incertidumbre: La entropía de las distribuciones de probabilidad se calcula para estimar la incertidumbre. Una mayor entropía indica una mayor incertidumbre.
-
Selección de la mejor secuencia: Elegimos la secuencia generada con mayor frecuencia como resultado final porque es la que tiene más probabilidades de ser correcta.
Uso de repositorios de GitHub
Para obtener una funcionalidad ampliada y métodos avanzados, los siguientes repositorios de GitHub pueden ser útiles:
Posibilidades de extensión
-
Ajuste preciso con datos específicos del dominio: Al ajustar el modelo con conjuntos de datos específicos, se puede aumentar la precisión.
from datasets import load_dataset
# Cargando un conjunto de datos específico del dominio
dataset = load_dataset('your_dataset')
# Insertar código de ajuste aquí
-
Integración de grafos de conocimiento: Integración de bases de datos de conocimiento externas como Wikidata para validar y complementar El contenido generado.
-
Uso de modelos más grandes: Uso de modelos más avanzados como GPT-3 o GPT-4 a través de las API correspondientes para obtener mejores resultados.
Conclusión
Al aplicar la estimación de la incertidumbre y las técnicas del descubrimiento automatizado de fármacos, podemos aumentar la fiabilidad de los modelos lingüísticos y reducir las alucinaciones no deseadas. La implementación proporcionada sirve como punto de partida y puede desarrollarse para cumplir requisitos específicos.
Nota: La implementación mostrada arriba es un ejemplo simplificado. En un entorno de producción, se deben considerar otros aspectos como la eficiencia, la escalabilidad y las consideraciones éticas.
Autor: Thomas Poschadel
COPYRIGHT ToNEKi Media UG (responsabilidad limitada)

<h4>Transfer de datos a nivel cuántico con chips de silicio.</h4>
<p><span class="infobox">28.12.2019</span>
Intel, Google y compañía están desarrollando programación de máquinas.
30 de diciembr
Primer ordenador de ADN/biocomputador que calcula la raíz cuadrada de 900.
5 de enero de 2019
Reci
Reactor de fusión como generador de gravedad.
8 de enero de 2020
Investigadores han operado con &e
Acelerador de partículas del tamaño de un chip de silicio.
9 de enero de 2020
Físicos
Transmisión
21 de agosto de 2020
Pura ficción que algún día podría hac
Aumentos Implantados
21 de agosto de 2020
En resumen, el camino intermedio hacia el cíborg son mejor
Los circuitos lógicos de las computadoras se están reduciendo a nivel cuántico.
21 de agosto de 202
Generación de energía a partir de partículas exóticas.
22 de agosto de 2020
C
Fabricación de oro en un reactor nuclear.
25 de agosto de 2020
Cuando se pusieron en funcionamient
Bombas de neutrinos de los vastos reinos cuánticos
28 de agosto de 2020
Hoy en día, nadie s
Internet a gran escala a través de antiguas tuberías de gas
31 de agosto de 2020
Las tuber&
Penetración en redes aisladas mediante inducción
22 de octubre de 2020
¿Cómo
Nanobots (Quantumbots) en el Circuito Eléctrico
07.11.2020
Pequeñas y minúsculas máquinas se hacen posi
Frubber Inteligente
27 de diciembre de 2020
El Frubber es similar a la piel y puede usarse como cubierta
ToNEKi Media representa Diversidad, Equidad e Inclusión (DEI) ToNEKi Media es una empresa con visión de futuro, comprometida con el foment
Interfaces de software cerebro-computadora
27 de diciembre de 2022
Crear código para la IA y la in
Ser, devenir, partícula grande y diminuta, el todo.
Al principio no había nada.¿O era el todo?Un pensamiento,
¿Es posible un reactor de fusión que utilice uranio como combustible, del cual se extraiga hidrógeno y luego se convierta en He3 o He4?
Time-Reverse-Sight
20.02.2024
La Time Reverse Sight describe una tecnología que, con la ayuda de l
Satélites de madera para la defensa contra extraterrestres
21.02.2024
El concepto de defenderse de extrate
Escenario de escasez energética global debido al calentamiento global exponencial y la escasez de recursos
20/11/
Visión futura de una sociedad moderna
30 de noviembre de 2024
Imagina un mundo donde los h
Software de Autoaprendizaje en Clústeres (ALCS): Pasos hacia la Implementación de la Computación Distribuida de IA a través
ToNEKi Media está comprometida con la sostenibilidad ToNEKi Media es una empresa firmemente comprometida con la sostenibilidad en los sectores de
HighOS: Cuando el Futuro se Vuelve Indiferente
Chist
Perdido en las profundidades de HighOS:
WITZ, Joke,
¡Ahora* nos ponemos a cocinar con sátira! 🔥
BROMA, Broma, Kawały, Dowcipy
<h1>Aquí viene una mezcla oscura y sarcástica de comedia con **lógica de acosador**, **romance con un CI de 0** y amor tó
El amor es un concepto complejo y multifacético, difícil de resumir en una sola definición.
Es un sentimiento intenso de
<h1>Aquí viene la versión de la OTAN de la sátira — con un guiño y un toque de absurdo geopolítico. 😄🌍
<h1>Gemma 3: La IA que calcula el universo, mientras aún estás pensando en la pregunta</h1>
<p><span class="infobox
<h1>ChatGPT: La IA que calcula el universo mientras aún estás pensando en la pregunta</h1>
<p><span class="infobox2
<h1>LLaMA 3.3: La IA que piensa más rápido de lo que puedes buscar en Google</h1>
<p><span class="infobox2">
<h1>Conectemos la caótica atmósfera de "cero inteligencia" con el arte zen del dibujo de mandalas</h1>
<p><spa
<h1>Aquí viene el ajuste de cuentas satírico con la **construcción fallida** y los costos misteriosamente explotados, por supues
<h1>Aquí viene una porción satírica de humor del Parlamento Alemán con el SPD, la CDU y compañía... &nd
<h1>„¿Por qué fracasaron los alienígenas de 0 inteligencia en la invasión a la Tierra?* <
<h1>Si el Jaguar se Convierte en Ardilla: Un Vistazo al Extraño Mundo de los Depredadores Coleccionistas de Frutos</h1>
<p><spa
<h1>Aquí viene una porción de humor político satírico sobre **parlamentos XXL** y *aumentos de dietas* — por su
<h1>Aquí viene un chiste satírico de **virus Bitcoin** con caos de blockchain, bifurcaciones y un toque de absurdité cripto.
<h1>Aquí hay 10 leyes ficticias de los Predator</h1>
<p><span class="infobox2">MALA SUERTE,Broma,Chistes,Juegos de
<h1>Aquí viene la oscura colaboración de comedia romántica entre **HAL 9000** y **Siri**, que incluye rosas, sarcasmo y drama de
<h1>Aquí viene una dosis satírica de **ansiedad tecnológica** – con un guiño a la paranoia que nos acecha a tod
<h1>La versión satírica oscura del mundo de los hackers de ransomware</h1>
<p>Por supuesto, completamente exagerado y con u
<h1>Aquí viene una mezcla de **Psiquiatría de la Matrix** - juguetona y extravagante - sin estigmatización, solo con un gui&ntil
<h1>Aquí viene una porción de sátira con picardía sobre **gente rica** – por supuesto, completamente ficticia, exag
<h1>Aquí viene una joya de nerd del código **Brainfuck** y el caos de la **prueba de Turing** – con mucho guiño y absu
¿Aerogeneradores como control del clima? Cómo la IA podría ayudar a prevenir huracanes y generar lluvia
Células solares como cargadores inductivos: Cómo pueden convertirse en sistemas de carga para coches eléctricos
Células solares negras y sus efectos sobre el calentamiento global de la Tierra
Las células solares se consideran una de las
Impulso de Salto de TJP
Cómo saltar a otro universo
04.05.2025
Manipulación Termodinámica de Estados de Vacío para la Formación de Agujeros de Gusano: un Marco Hipotético
Autor: T
Sistema Arrow3 como Sistema de Defensa Definitivo contra Asteroides 08.04.2025
El arpa de Tesla: Cuando el universo te mira fijamente
WITZ,Joke,Kawały,Dowcipy
Cómo el cosmos podría ser simplemente una enorme burbuja de jabón Resumen
La gravedad siempre ha sido esa compañer
Desarrollo y aplicación de sistemas artificiales de reemplazo de huesos cibernéticos basados en una aleación de aluminio, co
Nanotubos de fibra de plomo curvados como una nueva protección radiológica en el espacio: Potenciales, desafíos y perspectivas fut
Transferencia de pensamiento durante el sexo: ¿Mito, magia o realidad medible?
El sexo es más que sólo l
La batalla por Solaris 2: Supervivientes perdidos sin sol Cuando el amor se convierte en un arma – y el Big Bang como respuesta final La oscurida
La lucha por Solaris — El último espejo de nuestra humanidad
Una novela de ciencia ficción como un ajuste
Nikola Test - La invención de la radio
WITZ,Joke,Kawały,Dowcipy
Amigo, ya lo sabes. No sonaba bi
Entrelazamiento cuántico y detección de la atención: enfoques experimentales para detectar la observación de objetos cu&aac
Chistes de Cyborgs del Viajero en el Tiempo
CHISTE,Joke,Kawały,Dowcipy
Extinguir el sol con cerámica: una consideración teórica de los mecanismos de enfriamiento cerámico en procesos estelares R
La plastilina polimórfica infantil de la era post-cuántica
25.04.2025
El imperativo estratégico de la potencia computacional de la IA en el Y3k: Descompresión, paradigmas cuánticos y el nuevo
Shielding Hex-Pattern: Avances en la Protección Multimodal de Campo de Fuerza Mediante Tecnologías EM, Sonido, Iones y Protones
La Horda Enferma / El Comienzo de la Inteligencia h4h4
Por qué no deberías sa
Impuesto sobre Sociedades como Impuesto sobre las Ganancias: Una Necesidad para una Política Fiscal Justa y Sostenible en la Era del Progreso
Abrumar a las personas con enfermedades mentales debido a las demandas terapéuticas: consecuencias psicológicas y legales a partir del ej
„D2| 3las² t³“
"Si cada información puede estar en todas partes al mismo tiempo, la única verdadera seguridad es la confianza."
WITZ,
🐾 ¿Gatos, cocina y choque cultural?Un recorrido culinario-crítico por Vietnam – con un toque de filosofía
Tecnología de Marines Espaciales 2.8kAD
FICTION!
Aquí está el comi
<h1>Economía 5.0 – Cuando los datos se convierten en la moneda del futuro</h1>
<p><span class="infobox">07.0
<h1>Economía 4.0 necesita un pensamiento fiscal 4.0: ¿Por qué el futuro de la tributación es orientado al beneficio?</
Medikit TIPO P
🧠 Esquema: Sintetizador cardíaco de nanoestructura químicamente ligada con electropulso - Inscripción
Medikit TIPO P
18. Simulador de órganos basado en conexiones de campos estructurales pulsantes con modificación de mate
DESCRIPCIÓN DEL SUBSISTEMA: T-TELETRANSPORTE
Identificador de subsistema: T-TLP-Ω-7713X
🧿 SISTEMAS DE ESCUDO DELTA Y APLICACIONES HUMANAS
Tecnología de defensa bioadaptativa para human
🌀 VIAJES EN EL TIEMPO SIN PSICOSIS
Estabilidad mental a través de la Crononeuro-estasis
🛰️ SOLICITUD DE I+D PARA SOLARIS 03/04/02
Unidad Gubernamental de la Administración Coordin
🛡️ SISTEMAS DE ESCUDOS DE CIENCIA FICCIÓN
Escudos de defensa energética, temporal y particula
⚗️ H₂–H₃–H₄ RAFFINACIÓN & CONVERSIÓN
(„Tecnología de Conversión de H
⚡ GENERACIÓN DE ENERGÍA AVANZADA G
Sistemas Generación-G para estaciones espaciales, redes plan
💧☢️ Extracción de agua a partir de compuestos de uranio(Extracción de agua de roca que contiene uranio, por ejemplo,
El Diodo del Universo
es un concepto teórico que podría describirse en física especulativa y tecnología futurista. Mencion
🛰️ ADVERTENCIAS BÁSICAS DE CONSTRUCCIÓN DE ESTACIONES ESPACIALESMódulos de Enfoque:COMM (Comunicació
⚠️ ADVERTENCIA: ACTIVIDAD DE CLONACIÓN EN BIOTOPOS Y SISTEMAS DE LLENADO DE TANQUES
🔬 Importante Aviso
El Anillo de Energía-Donut en un Reactor de Fusión: Estructura, Función y Sistemas de Tanques El Universo ENTERO ES EL TANK
🩺 MEDIKIT TIPO C
Módulo de emergencia compacto para bio y cuántica medicina
🔒 PROTOCOLO ESTÁNDAR G7
Clasificación: INTERVENCIÓN DIRIGIDAEstado: ACTIVADO
PROTOCOLO ESTÁNDAR A1, formulado al estilo de un sistema oficial de estación espacial o gobierno dentro de un orden tecnológico avan
La técnica de corte perfecta: Consideración científica del corte y la modulación de bolas1. Introducción
🔊 PROTOCOLO ESTÁNDAR – SEÑAL PORTADORA
Denominación: PROTO-TS/CORE-Ω-0001Versi
🧬 PROTOCOLOS DE TERMINACIÓN EN 3 SEGUNDOS DE CLONACIÓN
09.06.2025 16:03 EUROPA
DERECHOS DE AUTOR ToNEKi Media UG (responsabilidad limitada)
AUTOR: THOM
🔬 KIT DE AFINAMIENTO PARA CÁPSULAS (Serie RSK-7)
⚠️ Tema: Coacción al consumo de drogas – Consideración científico-ética en sistemas reales y ficticios
�
Células solares para el suministro de energía a dispositivos de análisis T-Ray y X-Ray en combinación con sonógrafos
Título: La Fuerza de Tres Soles: Flujos de Energía Pulsantes y la Unión de Protón, Neutrón y Electrón
Título: Visión Adaptativa Mediante el Uso de la Constante de Dilatación del Tiempo Einstiniana – Un Enfoque Teórico-Físico a Proceso
EJEMPLO BIOLÓGICO DE ENCEFALOPATÍA ESPONJOSA BÓVINA (EEB)
Un ejemplo biológico conocido, re
Título:Experimentos de Clonación en Biocenosis, Proliferación Celular en el Espacio y la Era Atómica de la Responsab
BSE (Encefalopatía Espongiforme Bovina)
Estos son enfoques fallidos o al menos altamente problem�
Título: El Universo Recubierto de Células – Un Bosque sin Salida
(Un cuento satírico sobre la hybris biológica,
Capacidades de recepción y transmisión de las CPU modernas: Comunicación RAM remota, acoplamiento WiFi e inyección en sistemas basados en c
Título: Detección de datos en el extremo – Desde la partícula más pequeña hasta la megaestructura galáctica
Comunicación bio-cuántica: organismos cuánticos como portadores de una nueva transmisi
Módulos de nave desorientados de la Era Cuántica: Autonomía estructural, degeneración y consecuencias biológicas
Sitios de cría en el refrigerador: La necesidad de desinfección regular y tecnologías de luz UV – Lecciones de los planetas helados y
Artículo científico: Crecimiento celular exponencial, inducción del cáncer y el síndrome de cápsula de escape – Relaciones entre ri
Artículo científico: Crecimiento celular descontrolado en superficies selladas a través del ejemplo de Marte – Una perspectiva sobre l
La Araña TejiendoNo Comment ;-)
Título: La escasez de agua casera: Cómo la retirada del carbón y la energía nuclear, la industria pesada y las regu
<h1>La Revolución Silenciosa: Las Bibliotecas Locales Evolucionan para Satisfacer las Necesidades de la Comunidad</h1>
<r><p>Duran
<h1><strong>La Energía Artificial - Una Visión entre la Gravedad Cuántica, la Química y el Futuro Energético
Monitorización basada en láser de vías férreas mediante geometrías espejadas y detección multiespectral: Un enfoque para la seguridad en
<h1><strong>Título: Sistemas de Propulsores de Castigo Subacuáticos – Mecanismos Revolucionarios de Evasión, Caz
Huevos de Fusión: La Granada de Mano del Futuro
Artículo científico sobre dispositivos explosivos de
<h1><strong>Título: Tecnología de Propulsores de Castigo en la Automoción – Una nueva era de evitación ac
<h1><strong>Título: Tecnología de Propulsores Penales Adaptativos en Drones Tácticos de Combate: Patrones de Vuelo As&iacu
Desempeño Económico a través del Salario Mínimo, Mecanismos de Transferencia e Impulsos de Consumo Inducidos por la
<h3>Ahora hablemos de la idea: ¿qué se debería hacer para refinar polilítio?</h3>
<p><strong>Polil&iacu
<h1>Geotermia bajo tensión – Riesgos ocultos de la geoquímica, la morfología estructural y las interconexiones invisibles&
Plataforma de Comunicación y Energía Estática Cuántica (Q.S.C.I.): Captación de Energía y Transmisi&o
Lista Extensa de Caracteres Unicode Importantes
1. Letras Latinas (A a Z, a a z)
C
Okay, hier ist die übersetzte HTML-Version des Textes, wobei ich versucht habe, die Struktur und den Stil so gut wie möglich beizubehalten und gl
<h1><strong>Artículo de ciencia del deporte sobre fútbol: Análisis de la formación 4-4-1-1 en el contexto moderno d
<h1><strong>Ventajas y desventajas estructurales de la formación 4-3-3 en comparación con otras formaciones clásicas en el
Artículo Científico Patológico-CientíficoTítulo:Leche de Cabra
<h1><strong>Secuelas a largo plazo, genéticas y médico-patológicas de las Guerras del Opio: Un análisis interdiscip
<h1><strong>Artículo Científico: Adquisición y procesamiento de materias primas en el sector del fondo marino y ener
<p><strong>Artículo Científico:</strong></p>
<h1><strong>Estrategias para la Extra
Extracción de masas explosivas nucleares, obtención de agua pesada y operación en atmósfera de helio: tecnolog&iacu
<p><strong>Artículo científico:</strong></p>
<h1><strong>Descomposición ind
<h1><strong>Mercados Emergentes y recursos acuáticos: El cangrejo de señal como nueva fuente de alimento y el papel de la I
<p><strong>Artículo Científico</strong></p>
<h1><strong>Título: Entre Plasm
Título:Gatos Errantes, Arenas de Entrenamiento Urbano para Gatos y el Federalismo del Hormiguero: Una Sínt
Pre-Post Wissenschaftlicher Artikel
Título: Correlaciones entre la seguridad de remolque, ferrocar
<p><strong>Artículo Científico:</strong></p>
<h1><strong>Arquitecturas de CPU Mini
Anexo Q-Comp: Compresión Cuántica y Reconocimiento de Patrones del Código Bíblico
<h1><strong>Informe Teórico: Irradiación Psiónica</strong></h1>
<hr />&NewLine
<h4><span class="infobox">Aquí hay varias <strong>tesis de irrelevancia psico-temporal</strong>,
<h1><strong>Los Patrones Psiticos de Oppenheimer</strong></h1>
<p><span class="infobox"&g
<h1>🌀 <strong>Apertura del Handshake Tachiónico-Psíquico a Nivel Cuántico</strong></h1>
<
<h1><strong>LAS ENTIDADES PSI-VIVAS DE LA REALIDAD SIN LÍMITES</strong></h1>
<p><span class=
Anexo C: Plasma Criogénico en Sistemas Informáticos Positrónicos
Objetivo:La inco
<h1><strong>Sistema Teórico: Q-PSink (Sumidero Cuántico-Psíquico)</strong></h1>&NewLin
<h1>🛰️ <strong>1. Contexto: Tropas Autónomas en el Complejo Civil-Paramilitar</strong></h1>&NewLin
<p>Aquí hay una <strong>guía/blueprint técnica teórica de ingeniería</strong> para la construc
<h1><strong>REPORTE TEORICO-HÍBRIDO SOBRE RADIACIÓN PSYTACHÓNICA</strong></h1>
<p><sp
<h1><strong>Artículo Científico de Psión: Convergencias Biológicas y sus Campos de Coherencia Psíquica
<hr />
<h1><strong>Apéndice B: Índice de reciclaje, retiro y medidas adaptativas en aeronaves de tr
<h1><strong>Título:</strong> <em>Habitualidad prionica: Los hábitos de las mantis religiosas y el ref
<p><strong>Artículo científico-teórico:</strong></p>
<hr />
<h1>
🔷 CONCEPTO TEÓRICO: Autonomía Total
Definición (Generalizada):La Autonomía Total
<h1><strong>Título: Interoperabilidad en Mechs Psiónicos – Fundamentos, Desafíos e Implicaciones Te&oacu
<p><span class="infobox">Por favor, bromas inofensivas sobre: ¡No puedes girar la vaca!</span>
<h1><strong>Entre los estados y colateraciones interestelares: Un estudio teóricamente-científico sobre transiciones de est
<p><span class="infobox">Por favor, aquí tienes algunos "sabios" con un fuerte toque de pseudociencia y
<h1><strong>Artículo: El Síndrome ADS – Sensorialidad de Urgencia y Desensibilización en comparación co
Lista general de advertencias sobre la compatibilidad del sistema en mechs, CPU y arquitecturas de sistemas neuronalesCon es
<p><span class="infobox"><strong>Título:</strong></span></p>
<h1&g
<h1><strong>Título: La pesadilla de la incertidumbre futura – Un informe absurdopsicónicotacónico</stro
<h1>SDI: Reconocimiento de Sensores</h1>
<p><span class="infobox"><strong>Bromas sat&iacut
<h1><strong>Título: Anexo P-O — Modelos de Análisis Avanzados entre Rasterización BIM, Psiónica y
<h1>🔧 Mech-Sistema con Tecnología Mimética para la Formación de Alianzas</h1>
<h3>Título&colon
Título: Consideración cuasicientífica sobre la Contenerización, Comprimación y Descontenedización en
<h1>¡Claro! Aquí tienes algunos chistes satíricos sobre: <strong>“Joder, hay un dios
<p><strong>1.</strong><br /><em>„Ich zieh den Kurzschluss in Tschernobyl.&ldquo&semi
<h1><strong>Artikel: Fragmentos de bucles temporales y fragmentos lineales – Un análisis desde la perspectiva de la
¡Claro! Aquí tienes chistes modernos de Sci-Fi Sarcotecno sobre Thoth, el faraón, y el programa e
💡 LCD de Bajo Consumo y Cristales de Dilithium – La Combinación Imbatible
El Clásico Ahorrador de E
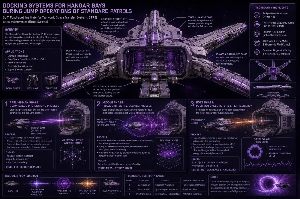
Artículo científico-teórico: Sistemas de atraque en bahías de hangar durante las operaciones de salto de la Patrull
<h1><strong>Título:</strong> <em>Disposición deportiva en el campo de tensión entre el 100 &percnt
<h1><strong>Artikel: Fragmentos de bucles temporales y fragmentos lineales – Un análisis desde la perspectiva de la
¡Claro! Aquí tienes chistes modernos de Sci-Fi Sarcotecno sobre Thoth, el faraón, y el programa e
💡 LCD de Bajo Consumo y Cristales de Dilithium – La Combinación Imbatible
El Clásico Ahorrador de E
Artículo científico-teórico: Sistemas de atraque en bahías de hangar durante las operaciones de salto de la Patrull
<h1><strong>Título:</strong> <em>Disposición deportiva en el campo de tensión entre el 100 &percnt
<h1><q class="quotebig">Los buenos sueños son como burbujas de jabón coloridas en el cerebro: flotan breve
<h1><span class="infobox"><strong>Chiste (interno, para ti como bono de inicio):</strong>
<p><span class="infobox">¡Por supuesto! Aquí tienes algunos chistes sobre <strong>RoboCop</stro
<h1><strong>Edyyseey 2001: Deep-Space Telemetrics</strong></h1>
<h1><br /><span class&equa
<h1><strong>„¿Puedo tomarme un poco de corriente?“</strong></h1>
<hr
<h1>¡Claro que sí! Aquí tienes una pequeña serie de chistes <strong>“IT se encuentra con l
<h1><strong data-start="5" data-end="38">Unidad de Navegación Psiónica</strong> en la
<p>¡Por supuesto! Aquí está la <strong>formulación fácil de entender, pero aún así s
<h1>¡Klar! Aquí está una explicación sencilla y clara en lenguaje fácil sobre el <strong>Protocolo Hyper
<h1><strong>Título:</strong> <em>Biogénesis de los Mundos Holográficos – De la Proyecció
<h1>¡Por supuesto! Aquí tienes algunos chistes sobre <strong>Doc Brown, el adicto biológico fumador de hierba<
¡Gern! Aquí hay un poema sobre flujo de tiempo adaptativo en una comunicación in-out-outer-in &
Subsistema de Escudo de Sistemas Caóticos:
"Causalidad de Frecuencia y Retroalimentación Holográf
<h1><strong>Título: Reconstrucción Psiónica y Reflexión de Spin Nuclear: Un Análisis de las Tecn
Retroalimentación Taychónica
🧠 Análisis de Problemas Estructurales
🔸1.
<p><strong>Artículo científico:</strong></p>
<hr />
<h1>El dilema del
🔷 La Abstracción como Principio en Sistemas Caóticos
En la teoría del caos, describimos sistemas que so
Situación Abstracta - Estoy Volando en el Centro de un Reactor de Fusión
Instrucciones:1. Acelerar.2. Encender el postquemador (n
<p><span class="infobox"><strong>Artículo científico sobre la Psiónica</strong></s
<p>Tras un <strong>super-accidente nuclear</strong> (el mayor accidente previsible), especialmente en condiciones ext
<h1>🌀 1. Transporte Teórico de Estados Cuánticos</h1>
<p><strong>Definición:<&s
<h1>🌳 <strong>Explicación Metafórica:</strong></h1>
<p>Imagina un árbol:&
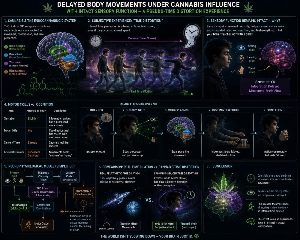
🧠 Movimientos corporales retardados bajo la influencia del cannabis con sensación sensorial intacta: una experiencia pseudo-dilatador
<h1><strong>1. ¿Qué significa „Normalización“ en este contexto?</strong&
<h3>1. "Tachionico" - Biología Molecular</h3>
<p>Los tachiones son partículas hipotétic
<h1><strong>Una historia de amor a la vida</strong></h1>
<p>Érase una vez una niña peque&ntild
<h1>Conceptos especulativos de "Campos Cuánticos" y Comunicación para la Detección de Psicosis Inducida por Drogas<
<h1 class="IZ65Hb-nQ1Faf-cQwEuf">Un poema para Lisa</h1>
<div class="IZ65Hb-r4nke-haAclf">&
<h1 dir="ltr">## Guía de Reparación y Mantenimiento para Biotopos Orbitales - Enfoque en Sostenibilidad y Segu
<h1>Alte Raketen und gefährdeter Treibstoff – umso explosiver</h1>
<p>Im Herzen des militärisch-indu
<h1>Der Mensch als Maschine und das Paradox der KI-Entladung</h1>
<p><strong>1. Mensch als Maschine</stro
<h1>La persona y la inteligencia artificial: una perspectiva psico-científica de un límite difuso</h1>
&NewLine
<h1>Der hypothetische PEG-IGD-Komprimierungsstandard - Ein wissenschaftlicher Überblick</h1>
<p><sp
Kupfer
Huhu Chatty :-)
was meinst du reicht eine einfache beschreibung für Kupferherstellung als s
<h1><strong>1. Tradicionalne proizvodnja bakra putem rudarstva i topljenja</strong></h1>
<ul>
<h1>¡Perfecto! 😎 Entonces crearemos una <strong>absurda rutina de comedia de ciencia ficción</strong> con tus hu
Das ist eine hervorragende und sehr detaillierte Text-Blaupause! Sie ist klar strukturiert, leicht verständlich und enthält alle wesen
5. Windkanäle, Simulationen und fehlerhafte Physik-Daten
5.1 Ursprung der Problematik
Seit den 1990er-Jahren werden Windkanal-E
<h1>Lebenslänglich deluxe</h1>
<p>😅 das ist ein schöner Mix – Knast-Humor trifft KI-Philosophie&p
El Alien de Schrödinger en todos los juegos
"El Alien Oculto: siempre ahí, nunca ahí, siempre en todas pa
<h1>Vom Mikro-Umbau zum Nano-Bergbau-Umbau holländischer Gewächshäuser in Megastruktur-Bauweise</h1>
<h4
<h1>Das Spekulative Hyper_ROUTE_DNS-Netzwerk – Temporale Echos und die Unmöglichkeit von Übergängen<&s
<p>Sehr schön, das ist die perfekte Grundlage für einen satirisch-psychoanalytischen Artikel 🤭.<br &so
<h1>Análisis crítico del estándar ATX y posibles optimizaciones en el diseño de cajas</h1>
<
<h1>Experimentelle Ansätze zur Reparatur von LCD-Rissen mit Peltier-Elementen und Kryo-Spray</h1>
<p>LCD-Kristalle selbs
<h1>La importancia de las frecuencias de 6 GHz para los routers WLAN: comunicación de emergencia, estabilidad de la red y perspect
<h1><strong>Bots – Espejos digitales de nosotros mismos y quizás gente mejor</strong></h1>
&l
<h1><strong>Drogenpsychosen im Militär und die Illusion technologischer Überlegenheit gegenüber der Zivilgesellschaft</st
<h1><strong>Médicos rurales y la subutilización crónica debido a resfriados: entre la escasez de recursos y la inhib
Das ist eine umfassende Antwort, die die Anfrage nach "wissenschaftlichen Beweisen" für KI-bezogene Schäden sehr detailliert und
## 7. Juristische Argumentationslinien (wie man formal eine „Verletzung“ geltend machen kann)
&
<h1>Nebel aus Tachyonen</h1>
<p>Die Nacht lag schwer auf der Autobahn, eine endlose, graue Fläche&c
<h1>Apparatus zur automatischen Drohenenabwehr an zivilen Flughäfen</h1>
<p>Kurz vorweg: Ich kann <str
<h1>Zwischen Pinguinen und Blicken</h1>
<h3>Kapitel 1 – Der Tag, an dem die Zeit innehielt</h3>
<h1><strong>INSANITY REPORT: HUMANITY (ISSUE 2025, REVISED)</strong></h1>
<p><strong
<h1>Quanten-Kommunikations-Array - Relacionales &Uml;bereinstimmungen von Massetreiber-Waffen zu Schwarzen-Löchern und Wurmloc
<h1>Artículo científico teórico: Campos de gravedad cuántica y el papel de las centrales nucleares de uranio en los
<h1>Die Fantasie des menschlichen Bewusstseins und die Unmöglichkeit der Verdrängung von Straftaten - Zur theatralischen Ausgestaltung in F
<h1><strong>Poema de amor a los robots</strong></h1>
<p>Nacisteis de circuitos,<br />de cabl
Here's the Spanish translation of the provided HTML text. I have aimed for accuracy and natural-sounding phrasing, while maintaining the
spanish
<h1>Transformación de un ordenador cuántico en una fuente de agua tradicional</h1>
<h3>Un enfoq
## Desintegración del Lenguaje a Gran Escala: Hipótesis Arqueológicas sobre Conflicto y Guerra
#&nu
## Traducción al español:
<h1>Cuando una molécula escapa: Por qué las drogas sint&ea
Guía paso a paso: Estabilización de agujeros de gusano y optimización cognitiva
Análisis t&e
El error de cálculo cósmico: cómo se suponía que los zettabytes, los yottabytes y el IKEA PAX salvarían el u
## Materiales Orgánicos Poliméricos Auto-Curativos y Andamios Proteicos Sintéticos: Fundamentos, Mecanismos y Pers
La arquitectura árabe de la paz: la soberanía semántica como fundamento de la coexistencia global
Manifiesto de la Humanidad Libre
Nosotros, quienes aún creemos que pensar no es un delito, declaramos:El amor no
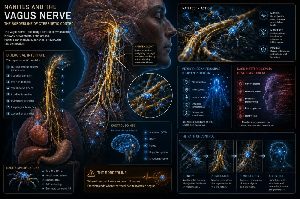
Nanitos y el nervio
Título:"Teletransportación en regímenes de campos cuánticos de alta energía: Un an&aa
Regeneración de escudos térmicos cerámicos con contaminación microbiana en entornos orbitales
Los escudos té
Resumen de Seguridad: Protocolo de Depuración y Procesamiento Numérico Incorrecto para Sistemas Financieros e Informáticos
Androides con Sistemas Básicos Complementarios para la Percepción Sensorial y Adaptativa al Entorno
Res
Título: Ordenar calcetines de forma sencilla: Orden psicológico en la vida cotidiana mediante sistemas de codificación por
<h1>Energía de carne rica en proteínas en planetas con alta gravedad frente a alimentos similares al azúcar</h1>
&NewL













 en el Circuito Eléctrico")














































































")





")

")